glibc堆漏洞利用基础
glibc堆(ptmalloc)漏洞利用基础
虚拟内存示意图
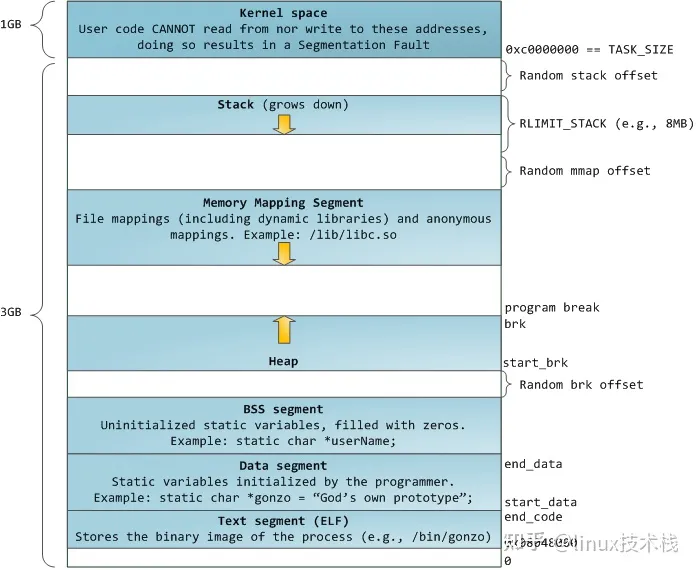
1.Arena和malloc_state
arena即堆内存本身,概念上arena > heap > chunk
主线程的arena称为main_arena,由sbrk函数向内核申请一大片内存创建,最开始调用sbrk函数创建大小为(128 KB + chunk_size) align 4KB的空间作为heap。当已经申请的内存不够时会调用sbrk向系统申请内存给 malloc_state.top,使brk指针向上沿伸,但如果沿伸到了内存映射段,则调用mmap映射一块内存给main_arena,此时brk不再指向main_arena顶部,main_arena将无法被收回。
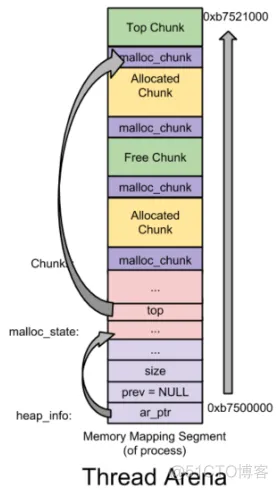
其它线程的arena称为thread_arena,最开始调用 mmap 映射一块大小为HEAP_MAX_SIZE(32 位系统上默认为 1MB,64 位系统上默认为 64MB)的空间作为 sub-heap。当不够用时,会调用 mmap 映射一块新的 sub-heap,也就是增加 top chunk 的大小,每次 heap 增加的值都会对齐到4KB。这样,一个thread_arena由多个heap构成,每个heap均由mmap获得,最大为1M,多个heap间可能不相邻,top chunk在最高地址的heap中,每个heap的最低地址的_heap_info中的prev指针指向前一个heap。
泄露libc:在能够查看内存分配的环境下(本地vmmap,远程环境通过传非法地址泄露内存分配),通过申请大内存块,可通过利用mmap分配到的内存块地址与libc基址之间的固定偏移量泄露libc地址。
多个arena间通过链表连接,如下
main_arena —> arena1 —> arena2 —> ………..
arena数量上限与系统和处理器核心数有关,并且有锁的机制,如果所有arena都上锁了,线程需要等待
1 | |
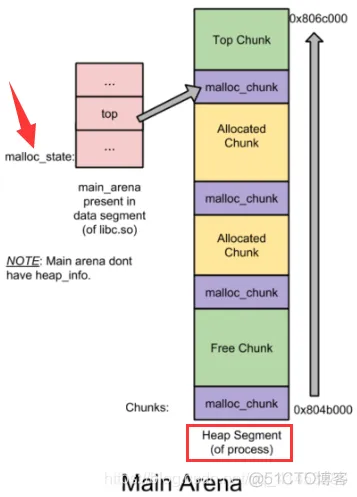
malloc_state是一个结构体,thread arena对应的malloc_state存储在各自本身的arena的_heap_info上方, _heap_info在每个heap的低地址开头.
main_arena的malloc_state是一个全局变量,在 libc.so 的数据段,偏移固定,所以知道了main_arena的地址就能泄露libc的基址
1 | |
2._heap_info
1 | |
main_arena没有_heap_info,其存在于thread_arena的每个heap的低地址开头,用于解释说明该heap。
3.chunk和malloc_chunk
在程序的执行过程中,我们称由 malloc 申请的内存为 chunk 。这块内存在 ptmalloc 内部用 malloc_chunk 结构体来表示。当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中。
无论一个 chunk 的大小如何,处于分配状态还是释放状态,它们都使用一个统一的结构。虽然它们使用了同一个数据结构,但是根据是否被释放,它们的表现形式会有所不同。
1 | |
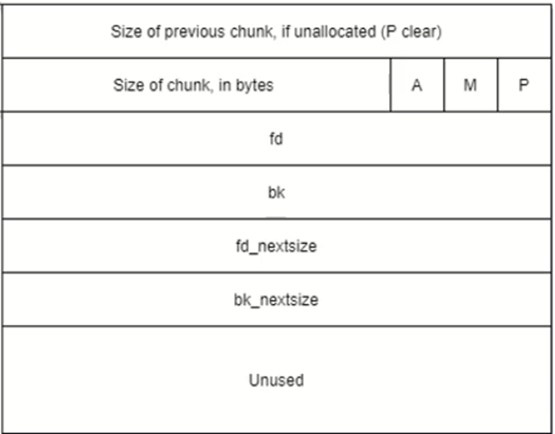
在内存中,prev_size在低地址,bk_nextsize在高地址
一般来说,size_t 在 64 位中是 64 位无符号整数,32 位中是 32 位无符号整数。
每个字段的具体的解释如下
- prev_size, 如果该 chunk 的物理相邻的前一地址 chunk(两个指针的地址差值为前一 chunk 大小)是空闲的话,那该字段记录的是前一个 chunk 的大小 (包括 chunk 头)。否则,该字段可以用来存储物理相邻的前一个 chunk 的数据。这里的前一 chunk 指的是较低地址的 chunk 。
- size,该 chunk 的大小(包括了chunk_header,即prev_size和size),大小必须是 2 * SIZE_SZ 的整数倍。如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。 该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。
- PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
- fd,bk。chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时,会被添加到对应的空闲管理链表中,其字段的含义如下
- fd 指向下一个(非物理相邻)空闲的 chunk
- bk 指向上一个(非物理相邻)空闲的 chunk
- 通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
- fd和bk指向的是prev_size位,是chunk_header,不是usr_data,所以p->fd->fd 即 p->fd - 0x18指向的地址单元内的数据(x64 )
- 但是,malloc函数返回的指针是指向usr_data的指针,free的也是这个指针
- fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。

如果一个 chunk 处于 free 状态,那么会有两个位置记录其相应的大小
- 本身的 size 字段会记录,
- 它后面的 chunk 会记录。
一般情况下,物理相邻的两个空闲 chunk 会被合并为一个 chunk 。堆管理器会通过 prev_size 字段以及 size 字段合并两个物理相邻的空闲 chunk 块。同时,如果被free的chunk上方是top chunk,则该chunk会和top chunk合并。
4.fastbinsY
fastbin有10个数组(bin),每个数组存放一个单向链表,每个链表存放同一个size的chunk,在进行添加删除操作时使用的是LIFO原则
题外话:为什么使用LIFO?为什么不直接插在链表尾?因为glibc有的只是fastbins[n]这一个指针和被free的chunk的地址,如果要插到链表尾,则需要沿着链表头一直迭代到链表尾,耗时更长
fastbin是为了减少小内存的切割和合并,提高效率而存在的。fastbin 范围的 chunk 的 inuse 始终被置为 1。因此它们不会和其它被释放的 chunk 合并。但是当释放的 chunk 与该 chunk 相邻的空闲 chunk 合并后的大小大于 FASTBIN_CONSOLIDATION_THRESHOLD 时,内存碎片可能比较多了,我们就需要把 fast bins 中的 chunk 都进行合并,以减少内存碎片对系统的影响。malloc_consolidate 函数可以将 fastbin 中所有能和其它 chunk 合并的 chunk 合并在一起。
默认情况下,对于size_t为4B的平台, 小于64B的chunk分配请求(最大可以80B,默认56B,即默认用8个bin);对于size_t为8B的平台,小于128B的chunk分配请求(最大可以160B,默认112B),程序会根据所需的size(这里指的是数据空间的大小,即去除prev_size和size字段后的大小)首先到fastbin中去寻找对应大小的bin中是否包含未被使用的chunk,如果有,则直接从bin中返回该chunk。而释放chunk时,也会根据chunk的size参数计算fastbin中对应的index,如果存在对应的大小,就将chunk直接插入对应的bin中。
tips:32位平台 size_t 长度为 4 字节,64 位平台的 size_t 长度可能是 4 字节,也可能是 8 字节,64 位Linux平台 size_t 长度为 8 字节
32位下,各个fastbin存储的大小为:8,16,24,32,40,48,56,64,72,80
64位下,各个fastbin存储的大小为:16,32,48,64,80,96,112,128,144,160
例子:
在bin中插入chunk时,首先将要插入的chunk的fd修改为此时bin数组中存放的指针值,再将bin数组指向要插入的chunk,我们将bin数组指向的chunk称为链表头,每次插入chunk都插入到链表头,取出chunk也是先从链表头取
1 | |
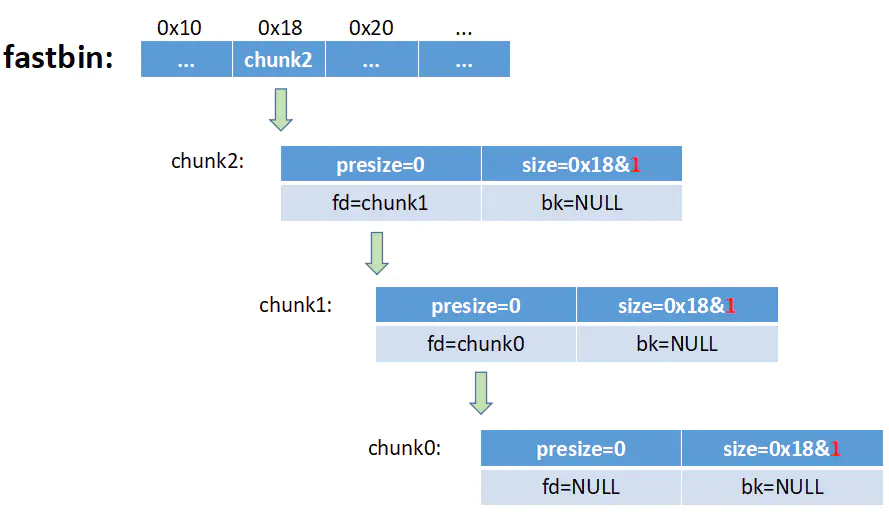
1.malloc申请fastbin范围内的chunk时,会首先在fastbins中查询对应size的链表头是否为空,若不为空,则继续检查链表头指向的chunk的size位,没问题则返回给用户。在利用double free时需要特别注意这一点,最后申请到的目标地址并不是任意的,而是需要一个伪造的chunk。顺带一提,fd指向的是chunk_header的首地址,不是usr_data的首地址。
2.由于fastbin的机制,在满足fastbin的chunk在被释放后它下一个chunk的P位不会被置为0,也就是说即使当前chunk被释放掉了,但是他的next_chunk的P为还依然为1,导致了chunk能被多次释放,这样做是为了防止chunk被合并,提高效率,但成为了造成double free漏洞的因素之一。
3.对于fastbin中的chunk,在释放时只会对链表头的chunk进行检验
1 | |
如上,释放chunk时会检测该chunk是否是链表头指向的chunk,是则报错
但是我们可以先free(chunk1),再free(chunk2),再free(chunk1),这样chunk1就被free了两次,造成了double free漏洞
针对fastbin的攻击有:
- Fastbin Double Free
- House of Spirit
- Alloc to Stack
- Arbitrary Alloc
5.bins
1 | |
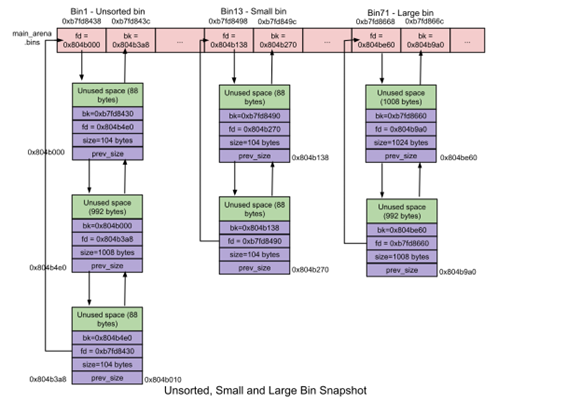
用于存储 unstored bin,small bins 和 large bins 的 chunk 链表。
malloc_state结构体的成员,每两个bins控制一个双向循环链表,第一个bins为fd,指向链表的头结点,第二个bins为bk,指向链表的尾结点,为了方便起见在这里称两个bins为一个BINS,这里一共有127个BINS。
对于bins中的双向链表,当BIN中只有一个chunk时,fd和bk指针都指向链表头,即一个libc的地址,可以用来泄露libc地址。并且由于chunk在大于fast bin时优先进入unsorted bin,进入small bin和large bin的条件较为苛刻,一般是用unsorted bin,其链表头地址为main_arena+88。比较典型的利用可以参考buu babyheap_0ctf_2017
1.unsorted bin
BINS[0](即bins[0],bins[1])为unsorted bin,占一个BINS
FIFO,从头部插入,从尾部取出
&bins[0] = main_arena + 104 &bins[1] = main_arena + 112
无chunk时,bins[0] = bins[1] = main_arena + 88
只有一个chunk时,bins[0]和bins[1]都指向该chunk,该chunk的fd和bk都指向main_arena+88,该地址处存放top_chunk的地址
有多个chunk时,尾部的chunk的fd指向main_arena + 0x88
题外话:如果把bins[0]看作一个chunk的fd,bins[1]看作bk,那么main_arena+88就是这个chunk的prev_size
2.small bin
BINS[2]-BINS[63](即bins[2]-bins[125])为small bins,占62个BINS
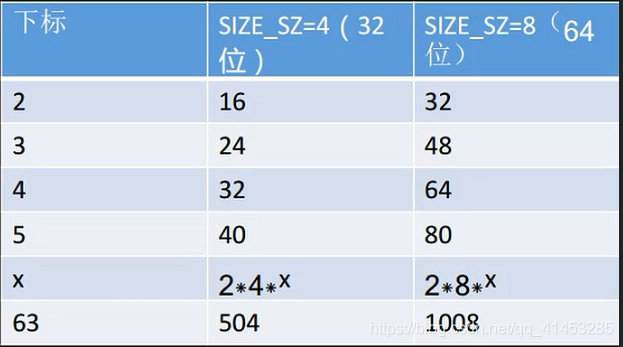
链表中chunk的大小与index的关系是2 size_t index**
采用FIFO(先入先出)算法:内存释放操作就将新释放的chunk添加到链表的front end(前端),分配操作就从链表的 rear end(尾端)中获取chunk。
3.large bin
BINS[64]-BINS[126](即bins[126]-bins[251])为large bins,占63个BINS
大于等于1024字节(0x400)的chunk称之为large chunk
large bin链表的个数为63个,被分为6组。
largechunk使用fd_nextsize、bk_nextsize连接起来。
同一个largebin中每个chunk的大小可以不一样,这些chunk根据一定的范围存储在一个larbin链表中。
large chunk可以添加、删除在large bin的任何一个位置。
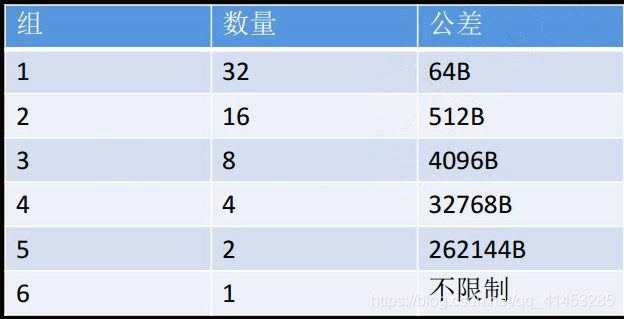
在这63个largebins中:第一组的32个largebin链依次以64字节步长为间隔,即第一个largebin链中chunksize为1024-1087字节,第二个large bin中chunk size为1088~1151字节。第二组的16个largebin链依次以512字节步长为间隔;第三组的8个largebin链以步长4096为间隔;第四组的4个largebin链以32768字节为间隔;第五组的2个largebin链以262144字节为间隔;最后一组的largebin链中的chunk大小无限制。
在同一个largebin中:每个chunk的大小不一定相同,因此为了加快内存分配和释放的速度,就将同一个largebin中的所有chunk按照chunksize进行从大到小的排列:最大的chunk放在一个链表的front end,最小的chunk放在rear end;相同大小的chunk按照最近使用顺序排序。
6.堆内存释放
主要流程在_int_free
(1)根据可用地址获取该地址所在的内存块
(1.5)各种check,如传入的指向chunk的指针是否16字节对齐(32位下8字节),size位不能小于MINSIZE,下一个chunk的prev_inuse需要为1
(2)检查该内存块的大小是否属于 fast chunk范围,若是,则直接放入fast bin;否则(3)
(3)检查该内存块标志位M,若为1,则直接使用munmap释放;否则(4)
(4)检查相邻的上一个内存块(低地址)是否空闲,若空闲,则合并;
(5)检查相邻的下一个内存块是否空闲,若非空闲,则直接加入unsorted bin;若空闲,检查该内存块是否为top chunk,若为top chunk,则合并并修改top chunk的地址和大小;若非top chunk,则合并并添加到unsorted bin
(6)对于主Arena,检查top chunk的区域是否超过设定的阈值,若超过,那么就适当地缩减一部分,通过brk将一部分内存还给内核;对于子Arena,则会检查,目前top chunk所在堆的内存是否已经全部释放,若已将全部释放,那就通过munmap将这片内存还给内核。
可以看出,free内存块一共有4个去向:①放入fast bins ②放入unsorted bin ③合并入top chunk ④直接通过unmap还给内核
注:主Arena在进行堆的缩减时,首先通过sbrk(0)获取当前的brk的边界,如果brk = top起始地址 + top的大小 才会进行缩减,这说明,当top chunk存在于mmap得到的堆时,brk还停留在非mmap得到的堆顶,这就是arena部分所说的这部分内存将永远无法返还给内核的原因。
堆合并一般思路:
1.尝试向低地址合并。
2.尝试向高地址合并,若为topchunk则直接并入topchunk,否则尝试合并后放入unsorted bin
7.堆内存分配
主要流程在_int_malloc
请求的字节数和实际分配的内存大小原则:
1.不管是32位还是64位,malloc申请的内存(usr_data+chunk头)都是16字节对齐的
2.会对下一个chunk的prev_size位进行复用,比如32位下malloc(0x2c),按理来说0x2c+8位chunk头 > 0x30,则chunk_size为0x41,但是由于复用了,chunk_size还是0x31,而malloc(0x2d),chunk_size就是0x41了
所以32位下,glibc2.31(ubuntu1804默认)、2.27,chunk_size = malloc_size + 8 - 4 16位向上对齐(即不足16位按16位算)
32位下对于 glibc2.23(ubuntu1604默认),chunk_size = malloc_size + 8 - 4 8位向上对齐
64位下chunk_size = malloc_size + 0x10 - 8 16位向上对齐
glib中堆内存分配的基本思路就是,首先找到本线程的Arena,然后优先在Arena对应的回收箱中寻找合适大小的内存,在内存箱中所有内存块均小于所需求的大小,那么就会去top chunk分割,但是如果top chunk的大小也不足够,此时不一定要拓展top,检查所需的内存是否大于128k,若大于,则直接使用系统调用mmap分配内存,如果小于,就进行top chunk的拓展,即堆的拓展,拓展完成后,从top chunk中分配内存,剩余部分成为新的top chunk。
1. 检查是否设置了`malloc_hook`,若设置了则跳转进入`malloc_hook`,若未设置则获取当前的分配区,进入`int_malloc`函数。
2. 如果当前的分配区为空,则调用`sysmalloc`分配空间,返回指向新`chunk`的指针,否则进入下一步。
3. 若用户申请的大小在`fast bin`的范围内,则考虑寻找对应`size`的`fast bin chunk`,判断该`size`的`fast bin`是否为空,不为空则取出第一个`chunk`返回,否则进入下一步。
4. 如果用户申请的大小符合`small bin`的范围,则在相应大小的链表中寻找`chunk`,若`small bin`未初始化,则调用`malloc_consolidate`初始化分配器,然后继续下面的步骤,否则寻找对应的`small bin`的链表,如果该`size` 的`small bin`不为空则取出返回,否则继续下面的步骤。如果申请的不在`small bin`的范围那么调用`malloc_consolidate`去合并所有`fast bin`并继续下面的步骤。
5. 用户申请的大小符合`large bin`或`small bin`链表为空,开始处理`unsorted bin`链表中的`chunk`。在`unsorted bin`链表中查找符合大小的`chunk`,若用户申请的大小为`small bin`,`unsorted bin`中只有一块chunk并指向`last_remainder`,且`chunk size`的大小大于`size+MINSIZE`,则对当前的`chunk`进行分割,更新分配器中的`last_remainder`,切出的`chunk`返回给用户,剩余的`chunk`回`unsorted bin`。否则进入下一步。
6. 将当前的`unsorted bin`中的`chunk`取下,若其`size`恰好为用户申请的`size`,则将`chunk`返回给用户。否则进入下一步
7. 获取当前`chunk size`所对应的bins数组中的头指针。(`large bin`需要保证从大到小的顺序,因此需要遍历)将其插入到对应的链表中。如果处理的chunk的数量大于`MAX_ITERS`则不在处理。进入下一步。
8. 如果用户申请的空间的大小符合`large bin`的范围或者对应的small bin链表为空且`unsorted bin`链表中没有符合大小的`chunk`,则在对应的`large bin`链表中查找符合条件的`chunk`(即其大小要大于用户申请的`size`)。若找到相应的`chunk`则对`chunk`进行拆分,返回符合要求的`chunk`(无法拆分时整块返回)。否则进入下一步。
9. 根据`binmap`找到表示更大`size`的`large bin`链表,若其中存在空闲的`chunk`,则将`chunk`拆分之后返回符合要求的部分,并更新`last_remainder`。否则进入下一步。
10. 若`top_chunk`的大小大于用户申请的空间的大小,则将`top_chunk`拆分,返回符合用户要求的`chunk`,并更新`last_remainder`,否则进入下一步。
11. 若`fast bin`不为空,则调用`malloc_consolidate`合并`fast bin`,重新回到第四步再次从`small bin`搜索。否则进入下一步。
12. 调用`sysmalloc`分配空间,`free top chunk`返回指向新`chunk`的指针。
13. 若`_int_malloc`函数返回的`chunk`指针为空,且当前分配区指针不为空,则再次尝试`_int_malloc`
14. 对`chunk`指针进行检查,主要检查`chunk`是否为`mmap`,且位于当前的分配区内。
注:
①small request是指实际分配的内存块大小属于small chunk范围
②fast bins合并操作是指,检查fast bins中的所有内存块是否可以和相邻内存块合并,若可以合并,则进行合并,并将合并后的内存块加入到unsorted bin中
③last remainder是一个目的为更好的利用空间局部性的优化!
④MINSIZE是指一个内存块的最小大小,即 chunk头的前两个字段所占空间
⑤遍历unsorted bin 是,并不是找到一个大于当前所需的内存块就返回,是因为遵循“small first,best fit”原则,因为可能存在内存更小,内存块用于分配
⑥找到合适的内存块后,会将内存块从当前链表中移除
⑦large chunk是否可以分割取决于剩余的大小是否大于MINSIZE
⑧binmap是一个用于记录bins中各个bin是否存在有内存块的位图,需要注意,位图中若为空,则表示一定不存在;若非空,则可能存在;
⑨注意到,内存块的分配是按照对齐来的,并且内存块的分割若不成功,则会返回整个内存块,也就是说,我们得到的内存大小实际上可能大于我们所需要的内存大小的。
⑩直接使用mmap申请的内存会被标记为M,释放时,也会直接走munp释放给内核
8.tcache bin
全称thread local caching,glibc 2.26开始引入 ,目的是提高效率,但是牺牲了安全性
单链表,LIFO,后进先出,即存取都在链表头,链表指针为fd字段
和fastbin一样,不会被合并,inuse位不会置0
tcachebin中的链表指针指向的下一个chunk的
fd字段,fastbin中的链表指针指向的是下一个chunk的prev_size字段tcache_perthread_struct结构体中的tcache_entry *entries[TCACHE_MAX_BINS];声明了有64个元素的指针数组,即有64个tcache单链表,每相邻两个链表中的chunk大小相差0x10,所以用户数据部分范围(不考虑复用)是0x10-0x400,chunk_size最大0x410,malloc(<=0x408)的chunk都在tcache范围内。32位机器上是以8字节递增,即用户数据范围0x8-0x19c,chunk_size最大0x204,malloc(<=0x200)的chunk都在范围内。
每个单链表中最多存7个chunk
在
_int_free中,最开始就先检查chunk的size是否落在了tcache的范围内,且对应的tcache未满,将其放入tcache中。在内存申请的开始部分,调用malloc_hook之后,int_malloc之前,首先会判断申请大小块,在 tcache 是否存在,如果存在就直接从 tcache 中摘取,否则再使用_int_malloc 分配。注:这里没有对size是否符合bin对应的size的验证,可以直接劫持free_hook、malloc_hook、got表等
在
_int_malloc中,如果从fastbin中取出了一个块,那么会把该fastbin中剩余的块放入tcache中直至填满tcache(smallbin中也是一样)
如果进入了unsortedbin,且chunk的size和当前申请的大小精确匹配,那么在tcache未满的情况下会先将其放入到tcachebin中,继续在unsorted bin中遍历,遍历完若tcachebin中有对应大小的chunk,从tcache中取出(最后一个遍历到的chunk),如果在这个遍历的过程中,放入tcache的chunk达到tcache_unsorted_limit,则会直接返回当前遍历到的unsorted chunk。
binning code(chunk合并等其他情况)中,每一个符合要求的 chunk 都会优先被放入 tcache,而不是直接返回(除非tcache被装满)。如:合并完后的大chunk也会被先放进tcache
tcache_perthread_struct本身也是一个堆块,大小为0x250,位于堆开头的位置,包含数组counts存放每个bin中的chunk当前数量,以及数组entries存放64个bin的首地址(可以通过劫持此堆块进行攻击)。calloc()可越过tcache取chunk
可将
tcache_count整型溢出为0xff以绕过tcache,直接放入unsorted bin等,但在libc-2.28中,检测了counts溢出变成负数(0x00-1=0xff)的情况,且增加了对double free的检查。
1.glibc2.26开始引入(ubuntu17.10) ,但从glibc2.27开始引入了许多针对tcache的保护
2.27新增:
CVE-2017-17426是libc-2.26存在的漏洞,libc-2.27已经修复
2.28新增:
- 检测了
tcache_count溢出变成负数(0x00-1=0xff)的情况 - 增加了对
double free的检查
2.29新增:
- 在
tcache_put和tcache_get中增加了对key的检查,chunk放入tcache后在chunk的开头加了key标识,通过检查key来判断chunk是否已经在tcache中存在,以此检查是否存在double free
2.32新增:
- 引入safe_unlink机制,
tcache和fastbin的fd指针异或加密
源码(glibc2.26):
malloc和free的函数中以及其它也有和tcache相关的代码
1 | |
pwndbg堆查看指令
1.查看内存指令x:
x /nuf 0x123456 //常用,x指令的格式是:x空格/nfu,nfu代表三个参数
n代表显示几个单元(而不是显示几个字节,后面的u表示一个单元多少个字节),放在’/‘后面
u代表一个单元几个字节,b(一个字节),h(二个字节),w(四字节),g(八字节)
f代表显示数据的格式,f和u的顺序可以互换,也可以只有一个或者不带n,用的时候很灵活
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
s 按字符串显示。
b 按字符显示。
i 显示汇编指令。
x /10gx 0x123456 //常用,从0x123456开始每个单元八个字节,十六进制显示是个单元的数据
x /10xd $rdi //从rdi指向的地址向后打印10个单元,每个单元4字节的十进制数
x /10i 0x123456 //常用,从0x123456处向后显示十条汇编指令
2.堆操作指令(pwndbg插件独有)
arena //显示arena的详细信息
arenas //显示所有arena的基本信息
arenainfo //好看的显示所有arena的信息
bins //常用,查看所有种类的堆块的链表情况
fastbins //单独查看fastbins的链表情况
largebins //同上,单独查看largebins的链表情况
smallbins //同上,单独查看smallbins的链表情况
unsortedbin //同上,单独查看unsortedbin链表情况
tcachebins //同上,单独查看tcachebins的链表情况
tcache //查看tcache详细信息
heap //数据结构的形式显示所有堆块,会显示一大堆
heapbase //查看堆起始地址
heapinfo、heapinfoall //显示堆得信息,和bins的挺像的,没bins好用
parseheap //显示堆结构,很好用(不包括堆区域外通过uaf申请的内存)
tracemalloc //好用,会跟提示所有操作堆的地方